Trusted by Market Leaders in Education, Travel, Finance and E-commerce since 2007





We put excellence, value and quality above all - and it shows






A Technology Partnership That Goes Beyond Code

“Arbisoft has been my most trusted technology partner for now over 15 years. Arbisoft has very unique methods of recruiting and training, and the results demonstrate that. They have great teams, great positive attitudes and great communication.”











Onshore vs Nearshore vs Offshore Software Development (US Buyers)


If you are a US buyer choosing between onshore development (US-based delivery), nearshore development (nearby time zones relative to the US), and offshore development (significant time zone separation), the most defensible way to decide is to treat geography as a proxy for constraints, not as a proxy for quality.
Two mandatory caveats up front:
- Geography is a proxy for collaboration constraints (overlap hours, travel feasibility, scheduling). Outcomes still depend heavily on vendor capability and governance.
- This article is general guidance, not legal advice. Contracts (MSA, SOW, IP terms) should be reviewed with qualified counsel.
A practical way to use this page: pick the model that fits your collaboration needs and risk profile, then validate it with a pilot that forces evidence (acceptance criteria, QA proof, delivery cadence, security posture) before you scale. If you want the broader selection method and scorecards, start with the buyer’s guide.
Where geography matters
Geography most directly affects the “collaboration physics” of an engagement:
- Overlap hours for real-time decisions (product, architecture, incident triage).
- Travel feasibility for workshops and milestone alignment.
- Scheduling friction across stakeholders (time zones, calendars, response windows).
Those constraints change how quickly a team can resolve ambiguity, validate assumptions, and unblock work.
Where geography matters less than most buyers assume:
- Quality and security are primarily practice-driven. Great and poor execution exist in every geography.
- Predictability is governance-driven when you have clear roles, testable acceptance criteria, disciplined reviews, and visible delivery signals.
- Secure software development is not inherently geography-bound. Treat it as an evidence problem: controls, artifacts, and proof you can inspect (not tool-brand claims).
Buyer-side readiness matters more than buyers want it to
Geography choices get blamed for problems that are often internal to the buyer org:
- If your product owner cannot make timely decisions, decision latency will rise even with an onshore team.
- If requirements change frequently but are not turned into testable acceptance criteria, more overlap can just accelerate churn.
- If your stakeholders are hard to schedule, “better time zones” do not automatically create alignment.
Before you pick a geography, be honest about the availability of your product leadership, SMEs, and security reviewers. Your governance model has to match your internal decision speed.
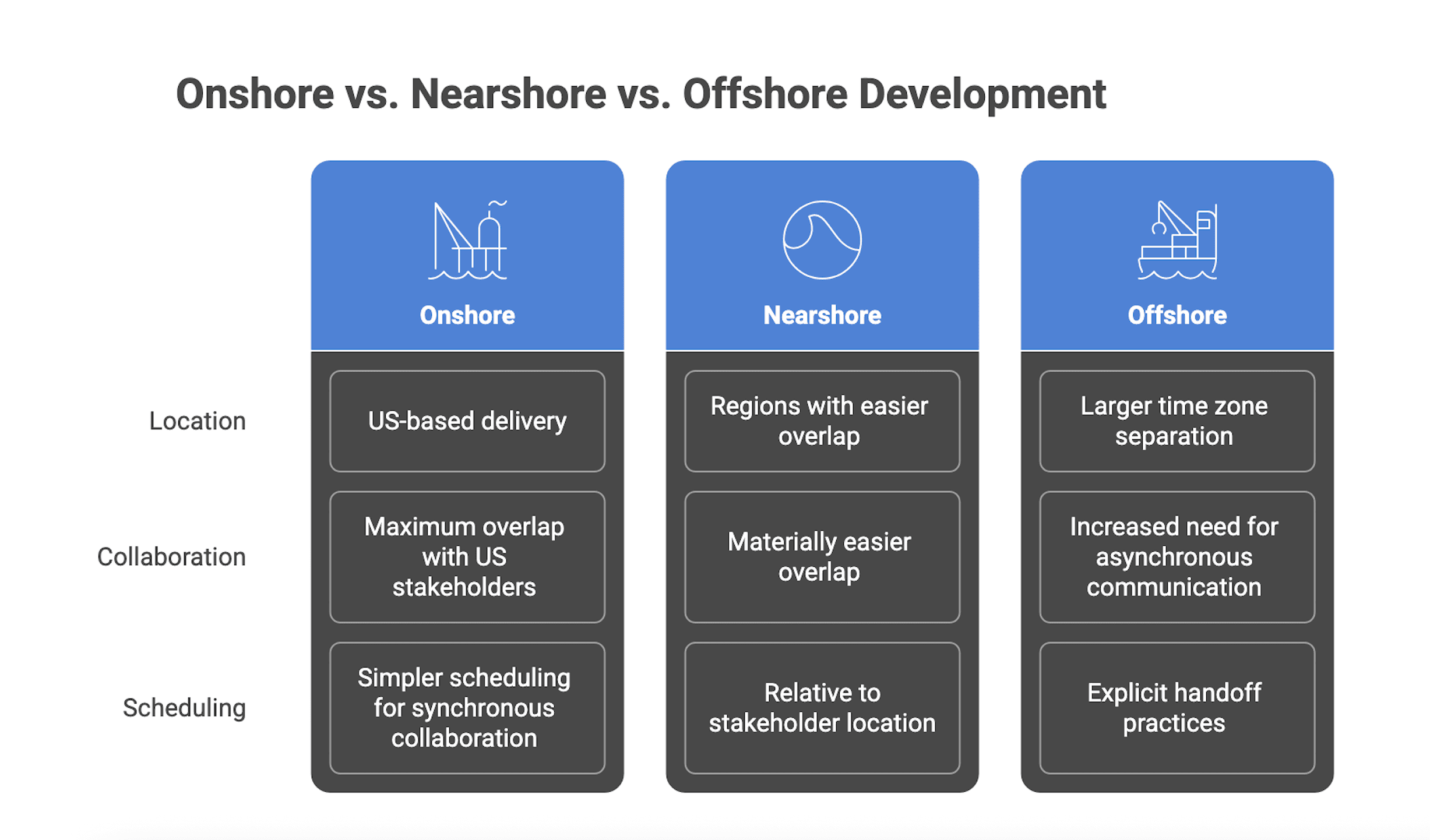
Quick definitions for US buyers
Onshore development (US-based delivery): Delivery primarily performed within the United States, typically enabling maximum overlap with US stakeholders and simpler scheduling for synchronous collaboration.
Nearshore development: Delivery performed in regions that enable materially easier overlap and travel compared to distant regions. “Near” is relative to where your stakeholders sit (US East vs US West matters) and to the actual overlap schedule the vendor commits to.
Offshore development: Delivery performed with larger time zone separation from core US stakeholders, which usually increases the need for asynchronous communication, written decisions, and explicit handoff practices.
Watch the edge cases
- A “US-based” vendor may operate a largely offshore team.
- A “nearshore” vendor can function like offshore if they do not staff overlap hours or if critical roles (product, architecture, QA leadership) are not available during buyer hours.
- Overlap is a negotiated operating constraint, not an intrinsic property of a geography. Treat unsourced overlap-hour claims as unreliable and insist the vendor specifies overlap in the engagement plan.
A simple definition test to align procurement, engineering, and security
Ask these four questions in your internal kickoff:
- What overlap hours do we require for product decisions, architecture reviews, and incident response?
- What work will be async-by-default, and what artifacts will carry the handoff (acceptance criteria, decision logs, runbooks)?
- Which roles must be available in US hours (product owner, tech lead, QA lead, security contact)?
- What is our travel assumption: none, quarterly, or key milestones only?
Then ask vendors: “Show a sample weekly calendar for ceremonies, overlap windows, and escalation availability.”
Quick Comparison
Dimension | Onshore (US-based) | Nearshore | Offshore |
| Potential overlap with US stakeholders | Highest | Negotiated, often easier | Negotiated, often harder |
| Async burden (writing, handoffs) | Lower | Medium | Higher |
| Travel feasibility for workshops | Easier | Easier than distant regions | Harder |
| Rate leverage (labor economics) | Typically lowest | Medium | Typically highest |
| Governance required to stay predictable | High | High | Very high |
The point is not that one is “best.” The point is which constraints you can realistically support.
The three trade-offs that actually drive outcomes: cost, risk, speed
Cost (beyond hourly rates)
Hourly rates are not your total cost. Total cost of ownership (TCO) often includes:
- Management and coordination overhead (buyer time and vendor time)
- Onboarding and ramp time (domain, codebase, environment access)
- Rework from misunderstood requirements or late defect discovery
- Attrition and continuity costs (knowledge loss, re-onboarding)
- Tooling and environments (CI/CD, testing, observability, security tooling)
- Security and compliance effort (evidence gathering, access controls, audit support)
A defensible principle: finding defects earlier generally reduces cost and effort compared to finding them late. That “shift left” mindset applies to delivery, too. Earlier clarity reduces later churn.
Where cost gets eroded fastest: ambiguous work with frequent change (discovery, UX iteration, integration-heavy modernization). In those cases, rework and decision latency become dominant cost drivers, and rate advantages can be overwhelmed by iteration inefficiency.
Context anchor (not a pricing model): the US Bureau of Labor Statistics reports a median annual wage of $133,080 (May 2024) for software developers. This helps explain why buyers explore nearshore or offshore. It does not translate directly into vendor rates or engagement savings.
Sanity-check cost realism by asking for evidence. Request vendor inputs that reveal the real operating cost:
- Team composition by role and seniority
- Weekly ceremony hours and who attends
- Overlap plan by role (product, tech lead, QA lead)
- Onboarding plan (access, environments, first backlog slice)
- QA scope and release cadence assumptions
- Definition of “done” that includes testing and acceptance evidence
Then add your own buyer-side cost: product owner time, SME time, security review time, environment provisioning time, and time spent clarifying requirements.
Risk (predictability, security, quality, IP)
When buyers say “risk,” they usually mean a bundle of concerns. Break it into categories you can verify:
- Delivery predictability: hitting milestones with scope control and transparent progress
- Quality: defect rates, defect leakage (bugs found late in UAT or production), maintainability signals
- Security and compliance: access control, secure SDLC practices, auditability, incident response readiness
- IP and confidentiality: preventing unauthorized access, leakage, or ambiguous ownership
- Continuity: turnover risk, knowledge retention, ability to sustain delivery
- Operational transparency: visibility into plans, changes, and real status
Security and compliance: treat it as “evidence you can inspect”
Instead of accepting marketing language, ask vendors to map their practices to outcomes-based expectations (for example, the NIST Secure Software Development Framework structure across Prepare, Protect, Produce, Respond). The buyer-friendly move is to request artifacts and controls you can evaluate.
If a vendor claims SOC 2, avoid treating it as a binary label. Ask:
- What is in scope?
- What period is covered?
- Which Trust Services Criteria categories are included?
- Can we review the report under NDA?
A small, organized proof pack is often lower risk than big promises.
Non-legal, practical IP and confidentiality risk reducers
This is not legal advice, but you can reduce exposure operationally by verifying:
- Least-privilege access (who can merge to main, who can access production secrets)
- Clear separation of environments and credentials
- Explicit ownership and change controls in your working agreements (and in your MSA/SOW with counsel)
Proof pack to request early
- Sample sprint artifacts (plan, backlog refinement notes, demo acceptance criteria)
- Sample PR review showing review depth and standards
- Lightweight QA summary report (test scope, defect trends)
- Decision logs (for example, architecture decision records) and incident postmortems if they run production systems
- Security questionnaire responses and summaries of SDLC controls, access control, vulnerability response
Speed (time-to-market vs iteration speed)
Speed is not one thing:
- Throughput: how much output a team produces
- Iteration speed: how quickly you can validate, learn, and adjust (feedback loop time)
- Calendar time-to-market: elapsed time to deliver a usable release
Geography affects iteration speed more than raw throughput because overlap constraints change decision latency. When overlap is low, “waiting for answers” stretches cycle time and increases rework. This is especially visible in discovery-heavy work.
Low-overlap can still be fast when designed for async execution
Offshore teams can maintain speed when the engagement is built around:
- Written decisions and documented acceptance criteria
- Clear interfaces and ownership boundaries
- Predictable review cadences (code review and QA evidence)
- Reserved overlap time for true blockers, not routine status
Metrics to establish (regardless of geography)
Agree on definitions and track a small set of signals:
- Lead time or cycle time (with agreed start and end points)
- PR review turnaround (median and tail)
- Defect escape or defect leakage trend (with a shared definition)
- Decision latency proxy (time from question raised to decision documented)
If a vendor cannot define or measure these, geography will not save the engagement.
Collaboration intensity: choose based on how much “real-time” you need
Collaboration intensity is a practical selector that avoids stereotypes.
High-collaboration work (needs more overlap):
- Discovery and ambiguous requirements
- UX iteration with frequent stakeholder input
- Complex stakeholder alignment
- Integration with unclear interfaces
Lower-collaboration work (can tolerate more async):
- Well-specified builds
- Mature backlogs with stable acceptance criteria
- Routine maintenance
- Some QA execution with clear test scope
- Well-defined services with stable contracts
A buyer diagnostic
- Are requirements stable and testable today, or are we still discovering the product?
- How often do stakeholders change priorities or acceptance criteria?
- How much cross-team integration is involved (APIs, data, security constraints)?
- What is our tolerance for 12 to 24 hours of decision latency?
A simple rubric
- Tier 1 (High collaboration): new product discovery
Prefer onshore or nearshore, or hybrid with onshore product leadership. - Tier 2 (Medium collaboration): known roadmap with some ambiguity
Nearshore or offshore can work with strong overlap windows and written artifacts. - Tier 3 (Low collaboration): maintenance with stable patterns
Offshore can work well with strong runbooks and clear service expectations.
Even execution-heavy work still needs some overlap for alignment and escalations. The question is how much overlap you need, and whether you can sustain it.
Scenario-driven Guidance
Below are eight mechanism-based scenarios. “Best fit” means likely fit if governance conditions are met, not a guarantee.
1) If you are budget constrained and scope is flexible (you can trade features for cost)
Consider: offshore or nearshore delivery with a strong buyer-side product owner; hybrid (onshore leadership plus offshore delivery pod) often fits.
Governance must be true: tight backlog hygiene, testable acceptance criteria, definition of done that includes testing, explicit overlap plan for decisions.
Validate: request a sprint 0 plan, sample acceptance criteria, and pilot one sprint scoring predictability and late-found defects.
Alternative: nearshore if the work needs more real-time collaboration than expected.
2) If you have an aggressive deadline and time-to-market is paramount
Consider: onshore or nearshore; or hybrid with onshore product and architecture plus parallel offshore build only when interfaces are clear.
Governance must be true: rapid decision-making, clear escalation, release readiness discipline.
Validate: ask for a delivery plan that includes QA and release steps, and inspect how PR reviews and testing hold up under time pressure.
Alternative: offshore can still work if scope is already well specified and the team is truly autonomous with clear acceptance criteria.
3) If you have heavy compliance or security expectations (regulated data, enterprise audits)
Consider: any geography can work if the vendor has verifiable controls. Buyers often prefer onshore or nearshore for perceived audit comfort, but evidence should dominate.
Governance must be true: access controls, auditability, secure build and release, incident response readiness, clarity on scope of attestations.
Validate: request a security proof pack and verify what is in scope, what period is covered, and what evidence exists for secure SDLC outcomes.
Alternative: hybrid with an onshore security or compliance lead plus nearshore or offshore delivery if responsibilities are explicit and evidence is strong.
4) If your work is discovery-heavy with ambiguous requirements (new product, changing stakeholders)
Consider: onshore or nearshore for discovery; hybrid with onshore discovery and offshore build after discovery outputs stabilize.
Governance must be true: facilitated workshops, documented decisions, prototypes, tight iteration cadence.
Validate: ask who runs discovery and what artifacts they produce, and request examples of decision logs.
Alternative: offshore can work if your internal product leadership can provide exceptionally clear written outputs and make fast decisions.
5) If you are modernizing legacy systems with unknowns (technical debt, undocumented behavior)
Consider: hybrid with onshore or nearshore technical leadership plus nearshore or offshore execution pods once the approach is mapped.
Governance must be true: interface contracts, migration plan with stage gates, strong regression strategy.
Validate: require a time-boxed spike plan with clear outputs, and confirm how they monitor defect leakage.
Alternative: onshore end-to-end if risk tolerance is low and domain knowledge is scarce.
6) If you need 24/7 support or operational coverage
Consider: offshore or multi-region coverage can help only if operational process maturity is high.
Governance must be true: incident response process, escalation paths, documented runbooks, measurable restoration expectations.
Validate: ask for sanitized incident postmortems and runbook excerpts, and how they institutionalize lessons.
Alternative: onshore with a paid on-call rotation if the system requires deep domain context that is hard to distribute.
7) If you have strong in-house tech leadership and need the vendor mainly for capacity
Consider: nearshore or offshore augmentation with clear boundaries; delivery pods aligned to internal tech leads.
Governance must be true: explicit ownership boundaries, PR review standards, definition of done, repo permissions and access controls.
Validate: pilot a small vertical slice and inspect integration with your workflows and code review expectations.
Alternative: onshore for the first phase if the codebase is highly coupled and onboarding is the real risk.
8) If procurement needs predictability and clear commercial terms (fixed budget constraints)
Consider: onshore or nearshore is commonly used; offshore is possible if scope is tightly bounded and acceptance criteria are explicit.
Governance must be true: strict change control, objective acceptance criteria, explicit QA scope.
Validate: ask how changes are handled and how acceptance is proven, and require a pilot sprint demonstrating acceptance discipline.
Alternative: hybrid where high-risk decisions stay in higher-overlap windows, while well-bounded execution is distributed.
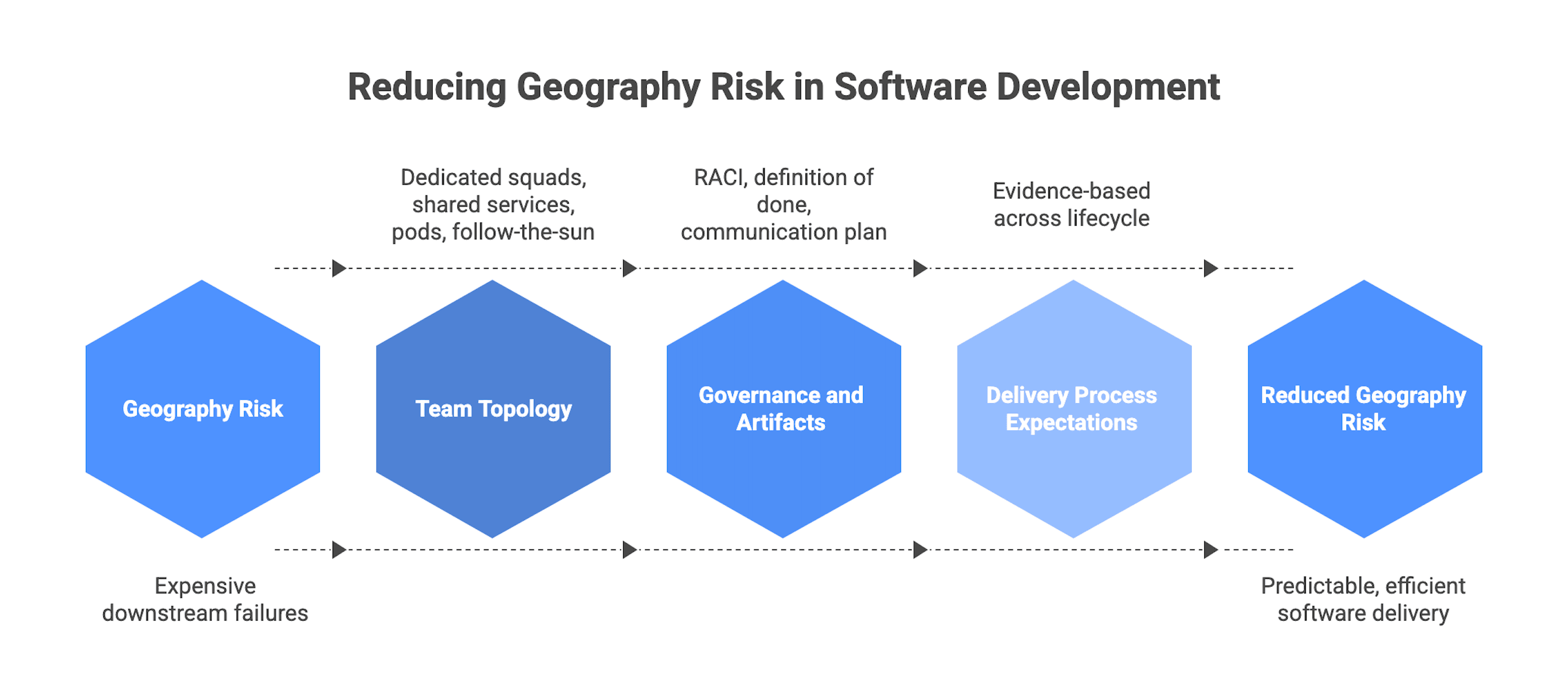
Operating models that reduce geography risk
Team topology options
Dedicated cross-functional squad (product, engineering, QA): often reduces coordination overhead because ownership is clearer and feedback loops are tighter. This tends to improve predictability for product-centric work.
Shared services (pooled QA, pooled architects): can improve utilization but increases dependency management and queueing. It can slow delivery when priorities shift or handoffs are frequent.
Pod-based delivery: scales when pods have clear interface boundaries and shared standards. Look for evidence of interface discipline and decision documentation.
Follow-the-sun: only credible when tasks are well specified, environments are reliable, and ownership is unambiguous. Otherwise it amplifies handoff waste.
More overlap is not free. If overlap is achieved through shift work, design it sustainably or you risk attrition and continuity issues.
Governance and artifacts
Governance is not a document pile. It is the minimum set of shared rules and artifacts that prevents expensive downstream failures.
Minimum artifacts that reduce risk across geographies:
- RACI (Responsible, Accountable, Consulted, Informed) with real decision rights and escalation timing
- Definition of done that includes testing and acceptance evidence (not “code complete”)
- Testable acceptance criteria for each backlog item
- Communication plan (ceremonies, channels, response-time expectations)
- Escalation path with time-bound ownership
- Change workflow for scope changes
If you want a deeper walkthrough of contract and governance mechanics (MSA, SOW, SLAs, IP, change requests), use the custom software development contracts & governance guide.
Delivery process expectations
Distributed delivery fails most often at handoffs and late QA. Keep expectations evidence-based across the lifecycle:
- Discovery: problem framing, prototypes, backlog with acceptance criteria, risks
- Build: working increments, PR-reviewed code, demo-ready slices
- QA: test scope and execution evidence, defect trends, agreed triage rules
- Launch: release readiness checklist, rollback plan where applicable
- Support: incident workflow, runbooks, postmortems
What to validate during vendor selection
If you do only one thing, make it this: evaluate what is inspectable.
Evidence that tends to predict success
- References for similar scope and engagement model (ask about cadence, predictability, quality)
- Sample deliverables and artifacts (sanitized sprint artifacts, PR reviews, QA reports, postmortems)
- Clear onboarding and overlap plan (calendar, roles, response times)
- Continuity plan (handover practices, documentation norms, backup staffing)
- Security posture evidence mapped to outcomes (controls and artifacts, not tool names)
Red flags that correlate with failure
- Vague staffing (“we’ll assign resources later”)
- Refusal to share any artifacts
- QA described only as “we test” with no scope definition
- Unrealistic timelines with no assumptions
- Unclear ownership and escalation
- “SOC 2 compliant” with no clarity on scope, period, categories, or evidence
Add one practical security check buyers forget: data residency and access
Without turning this into legal advice, ask:
- Where will environments and sensitive data reside?
- Who can access them, and how is least privilege enforced?
- How are secrets managed and rotated?
- What segregation exists between dev, staging, and production?
A lightweight pilot or POC (2 to 4 weeks) that forces reality
Goal: validate governance, collaboration, and quality signals early.
Pass signals:
- Clear acceptance criteria
- Predictable sprint delivery (planned vs done is explainable)
- Visible QA evidence
- Timely PR reviews
- Transparent risk escalation
Fail signals:
- Chronic ambiguity
- Delayed answers without written tracking
- Missing test evidence
- Repeated rework on the same misunderstandings
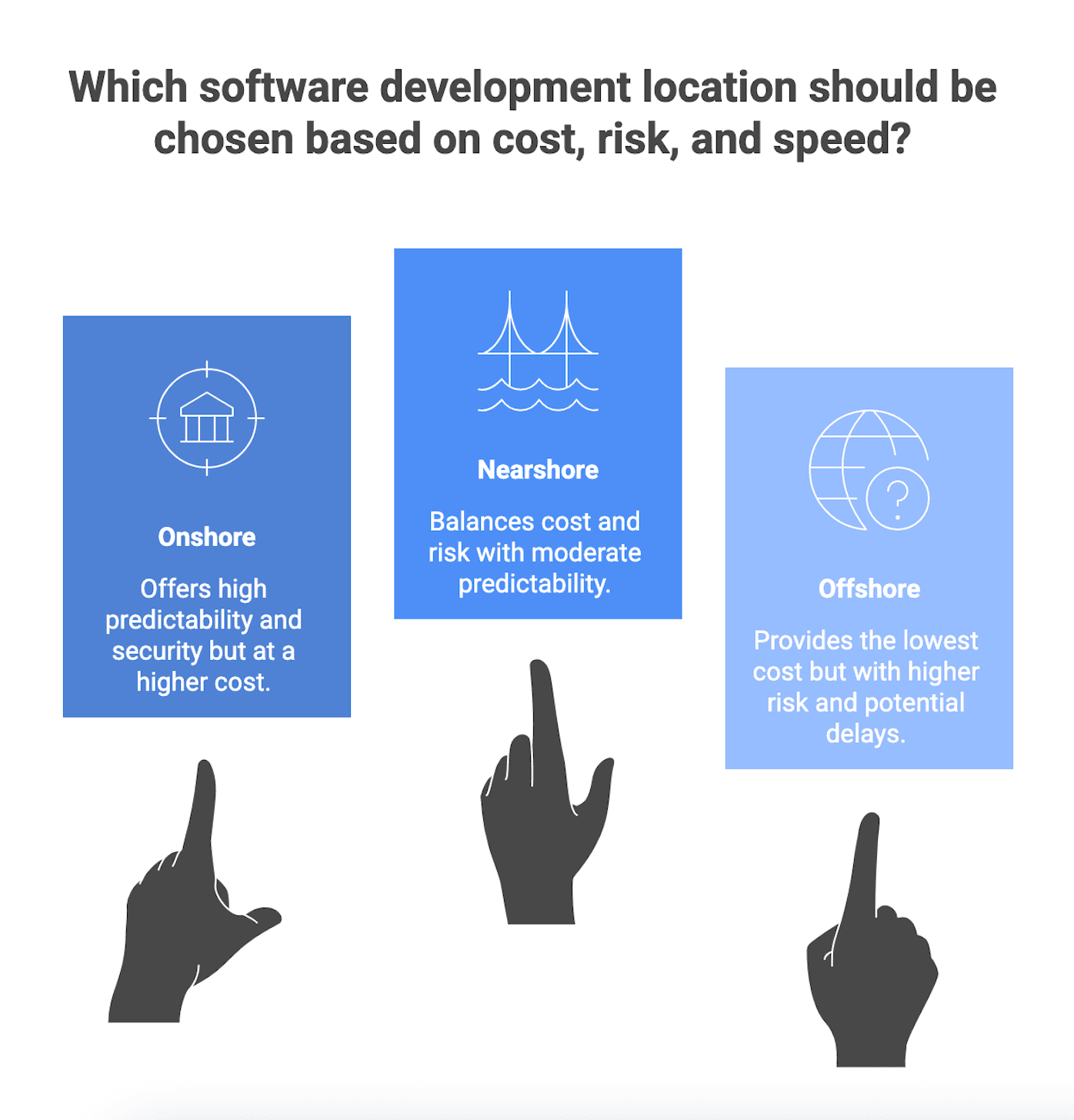
Bottom line: pick the geography that matches your constraints, then govern it well
There is no universal best geography model. Onshore, nearshore, and offshore are different ways of buying overlap, logistics, and cost structure. Outcomes depend heavily on governance and vendor maturity.
A defensible sequence after you pick a model:
- Define required overlap hours and what must be synchronous vs async.
- Require minimum governance artifacts in the first month (RACI, definition of done, acceptance criteria examples, comms plan).
- Run a pilot sprint with strict acceptance criteria and required QA evidence.
- Review early metrics (cycle time proxies, PR review time, defect leakage trend) and adjust the operating model before scaling.
If the vendor cannot produce evidence, switching geography will not fix it. Replace the vendor or redesign the governance.
Just published



