Trusted by Market Leaders in Education, Travel, Finance and E-commerce since 2007





We put excellence, value and quality above all - and it shows






A Technology Partnership That Goes Beyond Code

“Arbisoft has been my most trusted technology partner for now over 15 years. Arbisoft has very unique methods of recruiting and training, and the results demonstrate that. They have great teams, great positive attitudes and great communication.”











Why Custom Software Projects Fail: Top Causes + How to Prevent Them


Most custom software projects “fail” because delivery risk was never made explicit, owned, and managed, so it eventually shows up as budget burn, schedule slip, quality issues, missed business outcomes, and a breakdown of stakeholder trust.
It also helps to use precise language. Delivery frameworks commonly distinguish between:
- Successful: delivered on time, on budget, with full scope
- Challenged: delivered, but late, over budget, or with reduced scope
- Failed: cancelled outright
From a buyer perspective, “failure” usually means one or more measurable outcomes: budget overrun, timeline instability, missed business goals, defects that block adoption, or loss of executive sponsorship. And those outcomes are usually multi factor. What looks like a coding issue is often the downstream result of weak discovery, unclear ownership, uncontrolled change, or governance gaps.
The pattern underneath the chaos: failure usually starts before the first sprint
Large project data consistently points to the same thesis: the biggest drivers of distress are strategy and stakeholder management failures, plus weak technical and team management, and those issues compound over time rather than self correct.
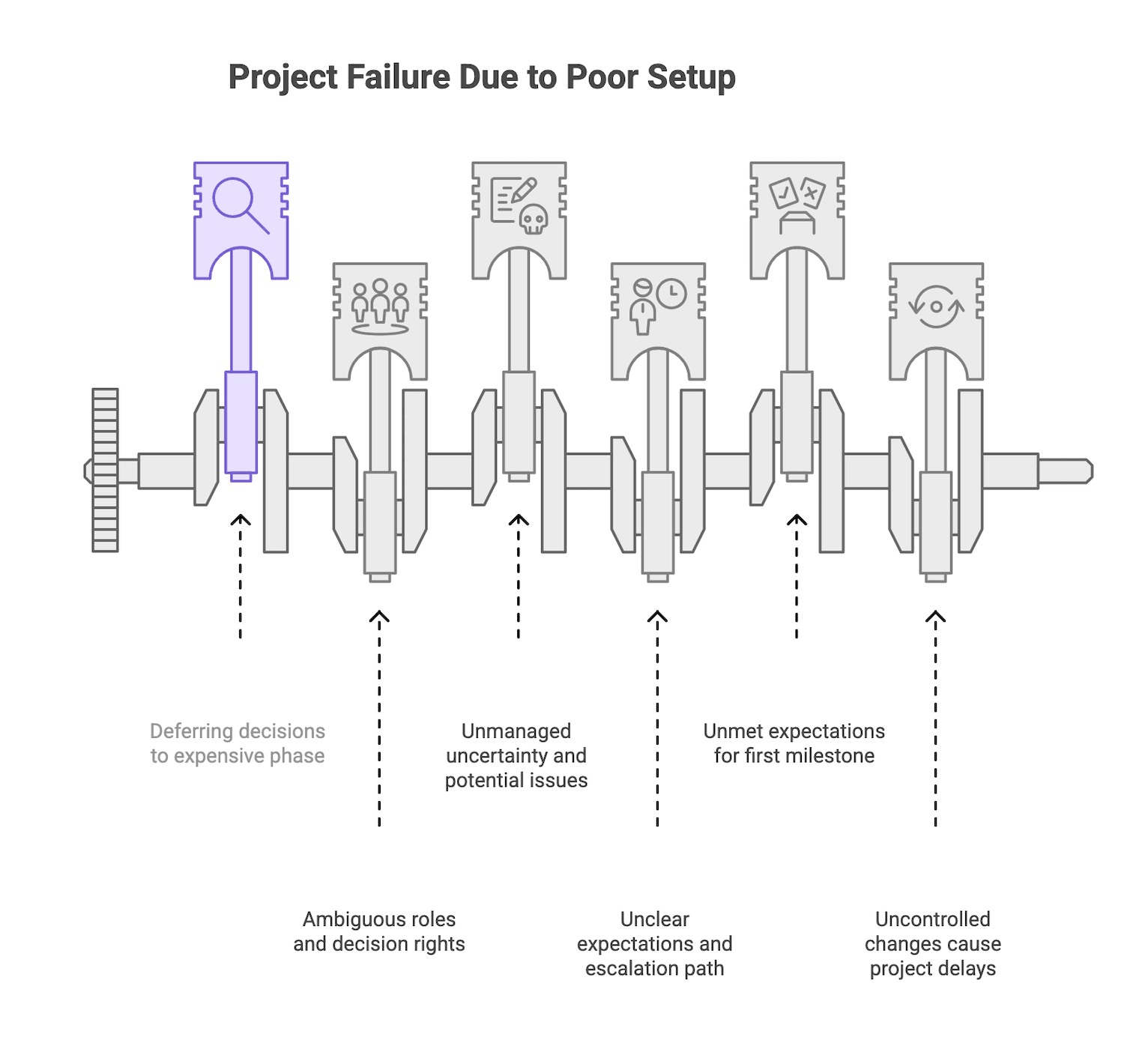
In practical terms, the “setup” matters more than most teams want to admit. If you start build work without clear scope boundaries, decision rights, a risk log with owners, acceptance expectations for the first milestone, and a change handling process, you are not moving faster. You are deferring decisions into the most expensive phase of the project.
A healthy engagement before sprint one usually has these basics in place:
- Scope boundaries and what is explicitly out of scope
- A RACI style role matrix and documented decision rights
- A risk log with owners and mitigations
- An agreed delivery cadence and escalation path
- Acceptance expectations for the first milestone
- A formal change handling process
If you do not have these artifacts, treat it as unmanaged uncertainty.
The top causes that derail custom software projects and the prevention moves that matter
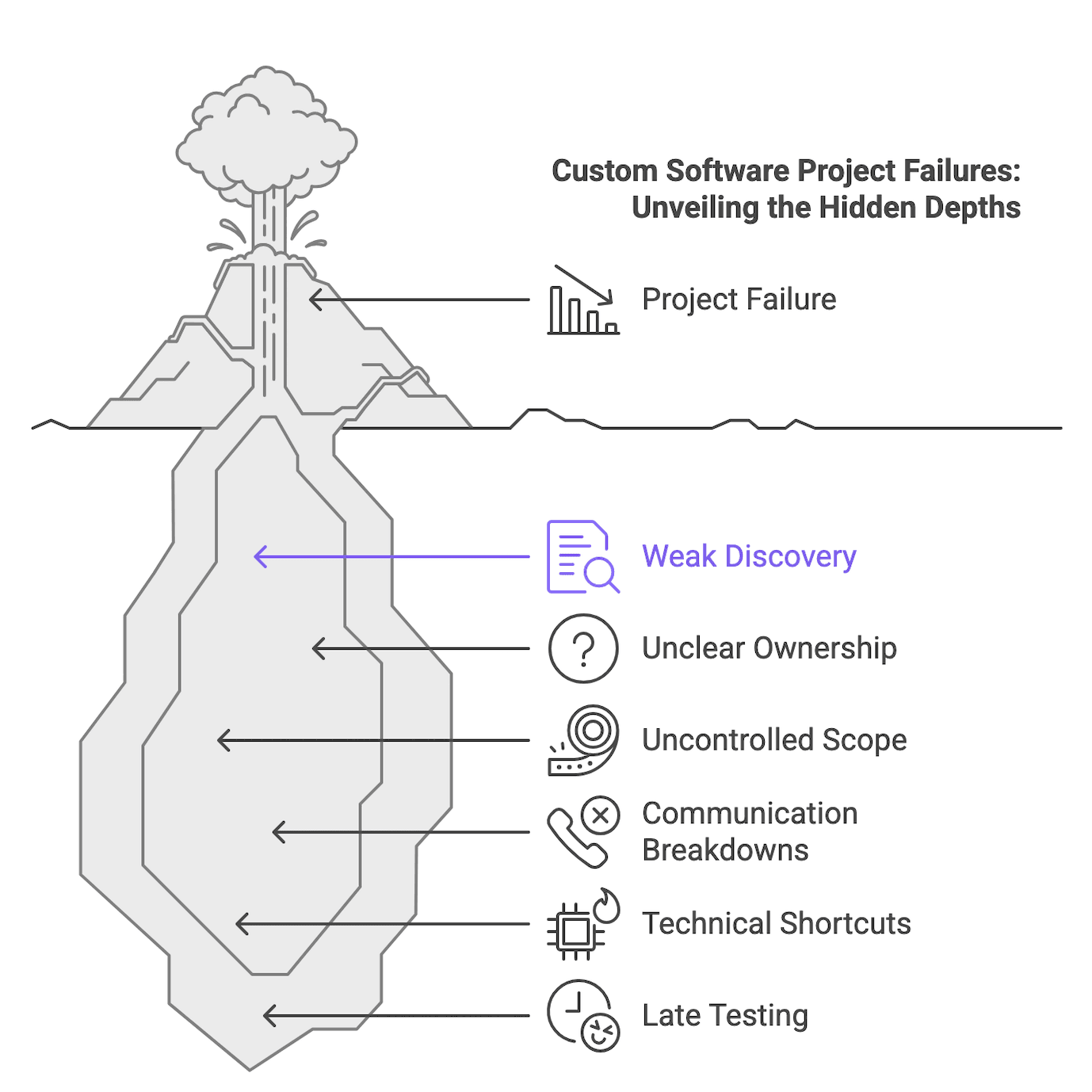
The failure modes below are stable across sources: weak discovery, unclear ownership, uncontrolled scope, communication breakdowns, technical shortcuts, and late testing. They also interact. Weak discovery feeds scope creep. Scope creep amplifies communication debt. Communication debt delays decisions. Delayed decisions increase rework.
Before diving in, one practical mindset shift: separate root causes from symptoms. “Developers are slow” and “the estimate changed again” are often symptoms. Your job as a buyer or sponsor is to identify which upstream system is failing: discovery, governance, change control, communication cadence, risk management, or quality gates.
Weak discovery turns estimates into guesses
In a healthy custom software engagement, the discovery phase produces concrete outputs: requirements specification, workflow maps, user personas, a technical architecture proposal, a risk register, dependency maps, and a preliminary budget estimate.
When discovery is shallow or rushed, teams miss legacy constraints, undercount integrations, assume incorrect business processes, and produce estimates based on assumptions rather than evidence. That is how projects end up with mid stream budget resets that feel like bait and switch even when nobody intended it.
Red flags you can spot early
- Discovery is shorter than two weeks for a complex build
- No written risk log or assumption log
- No workflow mapping
- A single point estimate instead of a range
- Estimates that do not trace back to specific discovery artifacts
Prevention moves that matter
- Require workflow maps and dependency mapping, especially around integrations
- Ask for an assumption log and confirm which assumptions were validated
- Ask for a risk log with owners and mitigations
- Expect estimates to reference artifacts
Trade off to acknowledge
Discovery costs time and money up front, but skipping it usually transfers cost into rework later. Discovery converts unknowns into a plan to reduce risk.
If you are already wobbling: recovery cue
If estimates keep changing without clear scope changes, pause feature expansion and run a structured reset: re validate workflows, integrations, and constraints, then re baseline scope and budget.
Unclear ownership slows decisions and compounds rework
Custom software projects require clear product ownership and defined decision rights. A simple rule is still the most useful: one accountable person per deliverable. When that does not exist, stakeholder sprawl takes over. Multiple voices request changes, conflicts do not get resolved, and developers build on assumptions to avoid blocking, which later turns into rework.
The cost is trust. Teams cannot create stable plans if decisions can be reversed by anyone at any time.
Early warning signs
- Sprint reviews end with “we need to align internally” every time
- Open questions stay open across multiple weeks
- Approvals are vague or verbal
- Contradictory direction from different stakeholders
Prevention moves that matter
- Require a RACI style matrix naming one empowered decision maker per workstream
- Define decision time expectations (for example, product decisions within X business days)
- Document decisions in writing and keep a visible decision log
- Define an escalation path for unresolved issues
Trade off to acknowledge
Broad input improves quality, but too many decision makers slows delivery. Centralized authority speeds delivery, but only works if the decision maker is informed by the right specialists.
Recovery cue
If decision latency is driving churn, reset governance before doing more build work. It is cheaper to fix decision rights than to rewrite features.
Scope expands faster than change control can absorb it
Uncontrolled scope growth is one of the most cited drivers of project failure. Often, “scope creep” is the symptom of unclear requirements, vague priorities, or absent change control.
The core issue is simple: when scope grows without an explicit adjustment to schedule or budget, quality becomes the hidden variable.
A practical approach is a formal change request process with two lanes:
- Fast lane for low effort, low risk changes
- Slow lane for anything that affects milestones, budget, or critical workflows
Prevention moves that matter
- Baseline scope before build begins
- Maintain a prioritized backlog
- Use a change request log with fields like effort estimate, schedule impact, approver, and decision date
- Require impact evaluation, not informal “we can squeeze it in”
Trade off to acknowledge
Iteration is normal. The difference between healthy iteration and damaging scope creep is whether changes pass through deliberate evaluation.
Recovery cue
If you have uncontrolled changes, stop accepting “small” requests until you have a working change control lane. Then re baseline scope to a Minimum Viable Product (MVP), meaning the smallest release that still achieves the outcome you care about.
Vendor and client teams create communication debt before they create working software
Communication breakdowns usually are accumulated mismatches in expectations, unclear definitions of status, and deferred clarifications, which become communication debt that compounds over sprints.
Healthier projects define a cadence such as:
- Weekly status
- Biweekly demos of working software
- Monthly steering reviews
- Clear escalation triggers and paths
The key is that status reporting should focus on validated outcomes. “We worked on feature X” is not the same as “feature X meets acceptance criteria and has been demonstrated.”
Prevention moves that matter
- Create a communication plan: cadence, reporting templates, escalation triggers
- Define “done,” “on track,” and “at risk” in plain language
- Require demos of working software regularly
- Match escalation level to decision scope
Trade off to acknowledge
Too many meetings reduces delivery time. Too little structure creates false confidence. Lightweight but consistent is usually the right balance.
Recovery cue
If status is always green but outcomes are not validated, shorten the reporting cycle, require demos, and force unresolved decisions into a steering forum.
Technical shortcuts create expensive surprises late in delivery
Technical debt is not automatically irresponsible. It becomes dangerous when it is implicit, unbounded, and unmonitored. Common late surfacing technical risks include architecture shortcuts, unvalidated integration assumptions, underestimated legacy constraints, and deferred non functional requirements such as performance, security, and scalability.
Defect economics matters here: bugs found late are far more expensive to fix than bugs found during design or early testing, and the effort increases sharply across phases.
Prevention moves that matter
- Document integration points and environment assumptions
- Define non functional requirements early
- Maintain a technical risk log with owners
- Add architecture review checkpoints before major build commitments
Trade off to acknowledge
Over engineering wastes budget. Proportional diligence means validating the riskiest assumptions early.
Recovery cue
If surprises keep appearing late, shift to technical triage: stabilize critical risks before continuing feature work. Rework is cheaper when done intentionally than when discovered during launch.
Testing and acceptance happen too late to protect launch quality
When acceptance criteria, Quality Assurance (QA) planning, and user validation are defined late, defects accumulate undetected and rework costs spike. Many defects originate during requirements, which makes early QA involvement essential.
Late testing often looks like:
- Vague acceptance criteria
- Back loaded QA cycles
- User Acceptance Testing (UAT) compressed into the last days
- Conflict over what “done” means
- Emergency patches and launch delays
Prevention moves that matter
- Define acceptance criteria alongside user stories before build begins
- Establish a test strategy, QA responsibilities, and a UAT plan
- Use release readiness checks with measurable entry and exit criteria
- Validate per sprint instead of a single final gate
Trade off to acknowledge
More testing is not automatically better. High risk modules (payments, security, data migration) need deeper coverage than low risk UI changes.
Recovery cue
If QA is becoming a bottleneck late, stop adding scope, define acceptance criteria for what is already built, then stabilize with staged acceptance and targeted defect fixing.
A simple map: failure mode to prevention, with recovery cues
The easiest way to keep this actionable is to tie each failure mode to a small set of artifacts and checkpoints. Use this as a review guide in kickoff and steering meetings.
Before the table: treat this as a diagnostic tool. Your goal is to surface uncertainty, assign ownership, and decide what you will do when risk shows up.
Failure mode | Early warning signs | Prevention artifacts to request | Fast recovery move |
| Weak discovery | Round number estimates, missing workflows, unknown integrations | Workflow maps, dependency map, assumption log, risk log | Structured reset, re baseline scope and estimate |
| Unclear ownership | Decisions stall, contradictory direction, no accountable approver | RACI matrix, decision log, escalation path | Governance reset, define decision rights and timing |
| Uncontrolled scope | “Small” requests pile up, repeated re estimates, quality drops | Scope baseline, prioritized backlog, change request log | Freeze intake, re scope to MVP, restart change control |
| Communication debt | Status reports show activity, surprises in reviews | Communication plan, definitions of done and at risk, demo cadence | Shorten reporting cycle, require demos, escalate blockers |
| Technical shortcuts | Late integration surprises, non functional issues appear late | Technical risk log, integration inventory, architecture checkpoints | Technical triage, stabilize critical risks first |
| Late testing and acceptance | UAT crunch, disagreement on “done,” defect spikes | Acceptance criteria, test strategy, UAT plan, release readiness gates | Define criteria, staged acceptance, stop adding scope |
After the table: if you only adopt one habit, make it this one. Insist on outcomes that can be validated, not progress that can only be described.
A late launch is not always a failed project, and a smooth kickoff is not always healthy
A project can launch late and still succeed if the delay buys risk reduction, quality improvement, or better market fit, and if scope and expectations were re planned through formal change control.
The opposite is also true. A kickoff can feel smooth because nobody has forced hard questions into the open. Polished decks and optimistic status can hide the fact that uncertainty has been deferred rather than reduced.
To avoid false confidence, watch trend indicators and validated outcomes:
- Are acceptance criteria being met each sprint?
- Is the risk log active and owned?
- Is working software being demonstrated regularly?
- Are cost variance and schedule variance improving or worsening?
If the answer is consistently “we will know later,” you are looking at unmanaged risk.
How buyers can reduce failure risk before kickoff and recover faster when a project starts wobbling
This is the prevention and recovery playbook buyers usually ask for: what to do before you sign, what to monitor during delivery, and what to do when the engagement starts to drift.
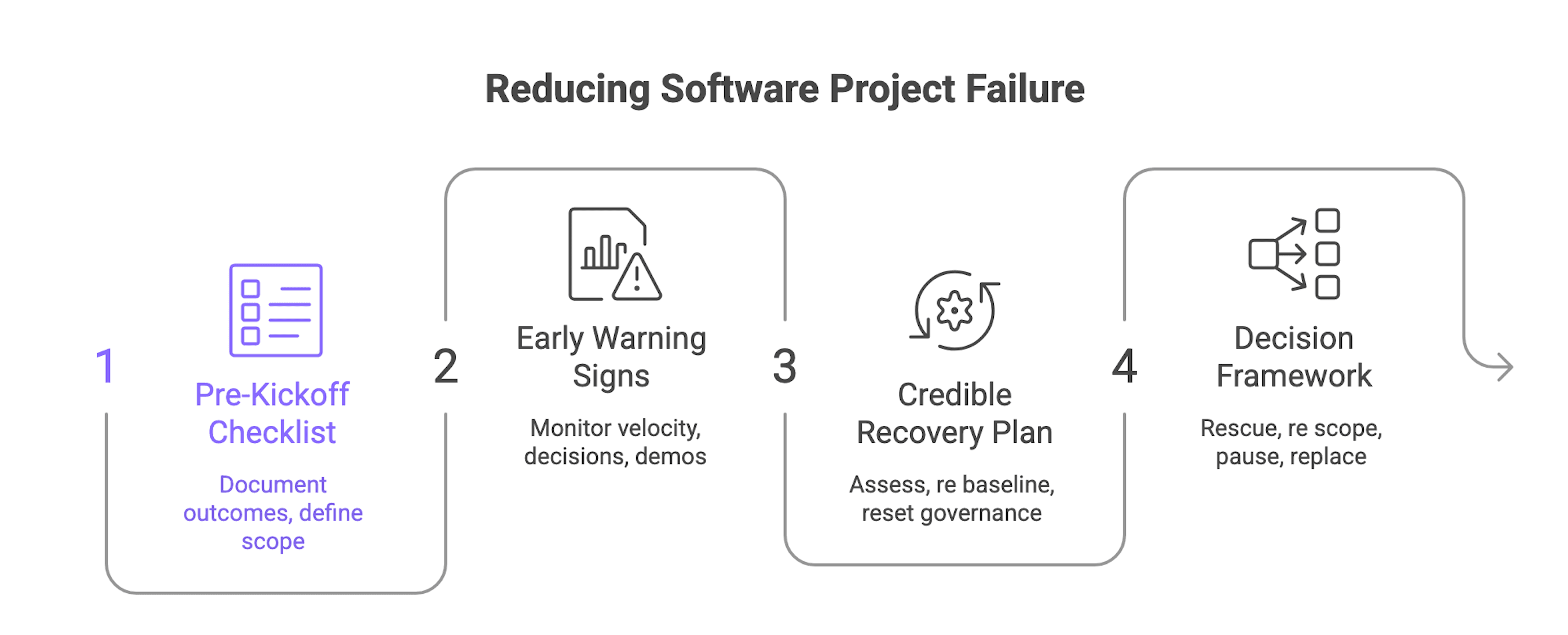
Before kickoff: a buyer checklist that reduces downstream failure risk
Use this as a gating function. If multiple items are missing, treat it as a signal to pause and reset.
- Business outcomes and measurable success criteria documented
- Single empowered decision maker identified per workstream (RACI or equivalent)
- Discovery artifacts reviewed: requirements, workflows, risk log, architecture, dependency map
- Scope baseline and change control process agreed in writing
- Communication plan: cadence, reporting template, escalation triggers, shared definitions
- Acceptance criteria for the first milestone defined before build begins
- Budget and schedule contingency explicitly allocated
If you also need the broader partner evaluation context, use the buyer’s guide for the full selection framework. This article stays focused on failure modes and how to prevent them.
Early warning signs that the project needs recovery
Small course corrections are normal. These indicators suggest the project needs a recovery plan:
- Repeated estimate revisions without corresponding scope changes
- Mounting unresolved decisions
- Status reports with no demonstrated working software
- Declining team velocity with no clear cause
- Stakeholder disengagement
When you see two or more of these at once, treat it as a system problem. Fixing one symptom rarely helps.
A credible recovery playbook
A recovery plan should be structured and time bounded. It is not a vague “we will work harder.”
- Rapid current state assessment
Review code, documentation, requirements, risks, and environments to determine what is real versus assumed. - Re baseline to the minimum viable outcome
Define the smallest outcome that still delivers value, then map scope to it. - Governance reset
Re establish decision rights, meeting cadence, escalation triggers, and who can approve changes. - Communication reset
Shorten reporting cycles, shift reporting toward validated outcomes, and require regular demos. - Technical triage
Stabilize critical risks such as integrations, performance, security, and data migration before resuming feature expansion.
Decision framework: rescue, re scope, pause, or replace
When the engagement is distressed, you need a decision.
- Rescue when the codebase is salvageable, the team has capacity, and the business case still holds after re baselining.
- Re scope when the original ambition exceeded realistic capacity but a smaller release still delivers value.
- Pause when governance has collapsed and a reset is needed before further spend is justified.
- Replace when trust has eroded beyond repair or the vendor cannot demonstrate a credible recovery capability.
The hard part is timing. Intervening too late makes recovery far more expensive because overruns compound over time.
Additional risk areas buyers often underweight
The research also highlights practical gaps buyers should address, even though they are not always discussed in delivery checklists. Treat these as “ask and verify” topics rather than assumptions.
- Contract structure and risk allocation: Make sure the Statement of Work (SOW) clarifies scope boundaries, change handling, acceptance, intellectual property, and termination paths.
- Team composition and key person risk: Confirm seniority on critical workstreams and whether delivery depends on one individual.
- Data migration and legacy constraints: Call out data migration, integrations, and environments explicitly as high risk areas and validate early.
- Adoption risk after launch: Plan feedback loops and validation so “shipped” does not become “unused.”
These topics do not replace discovery and governance. They sharpen them.
You do not need a full methodology debate to reduce failure risk. You need clear stages, clear gates, and a habit of validating outcomes.
- For disciplined handling of change requests so scope does not quietly eat budget and timeline, see Managing Scope Creep in Custom Software Development.
Conclusion: treat failure prevention as risk management
If you want fewer surprises, insist on a small set of behaviors:
- Evidence based discovery
- Clear decision rights
- Formal change handling
- Communication that proves outcomes
- Early risk validation for technical assumptions
- Acceptance criteria and QA planning from the start
Projects that do these things still face uncertainty. They simply do not let uncertainty turn into unmanaged risk.
Just published



