Trusted by Market Leaders in Education, Travel, Finance and E-commerce since 2007





We put excellence, value and quality above all - and it shows






A Technology Partnership That Goes Beyond Code

“Arbisoft has been my most trusted technology partner for now over 15 years. Arbisoft has very unique methods of recruiting and training, and the results demonstrate that. They have great teams, great positive attitudes and great communication.”











Eighty-eight percent of AI vendors are still doing pilots. Here's how to find the twelve percent who ship


TL;DR
Most AI vendors are great at demos and pilots. Here's how to screen for the ones that actually run live systems.
- 88% of AI proofs of concept never reach widescale deployment, per IDC and Lenovo
- That stat describes the market, not a headcount of vendors
- The gap between pilot and production is where AI projects die
- Ask for anonymized production artifacts before you ever watch a demo
- A shipped system has four traits: owners, users, controls, and consequences
- Talk to whoever inherited the system six months after launch, not the exec sponsor
- Weak answers sound hypothetical: "We would normally" or "The client handled that"
Lead the first vendor call with operations questions, not capability questions.
Introduction
The 88 percent number needs careful handling. IDC and Lenovo research found that 88 percent of artificial intelligence proofs of concept did not reach widescale deployment, roughly four production deployments for every 33 POCs. That is not a direct census of AI vendors.
But it does describe the market buyers now face: most AI activity still happens before production, and many vendors have learned how to sell that stage well.
The screening question is not, "Can this vendor build an impressive demo?" It is: can this AI engineering partner prove they have owned the messy work after the demo becomes a live system?
Start by separating pilot activity from production ownership
A vendor cannot prove they ship if the buyer lets them define "shipped" after the sales process begins.
Define production before the first call. In enterprise AI, production means a system is integrated into real workflows, used by real users, monitored under real operating conditions, and owned by named people after launch.
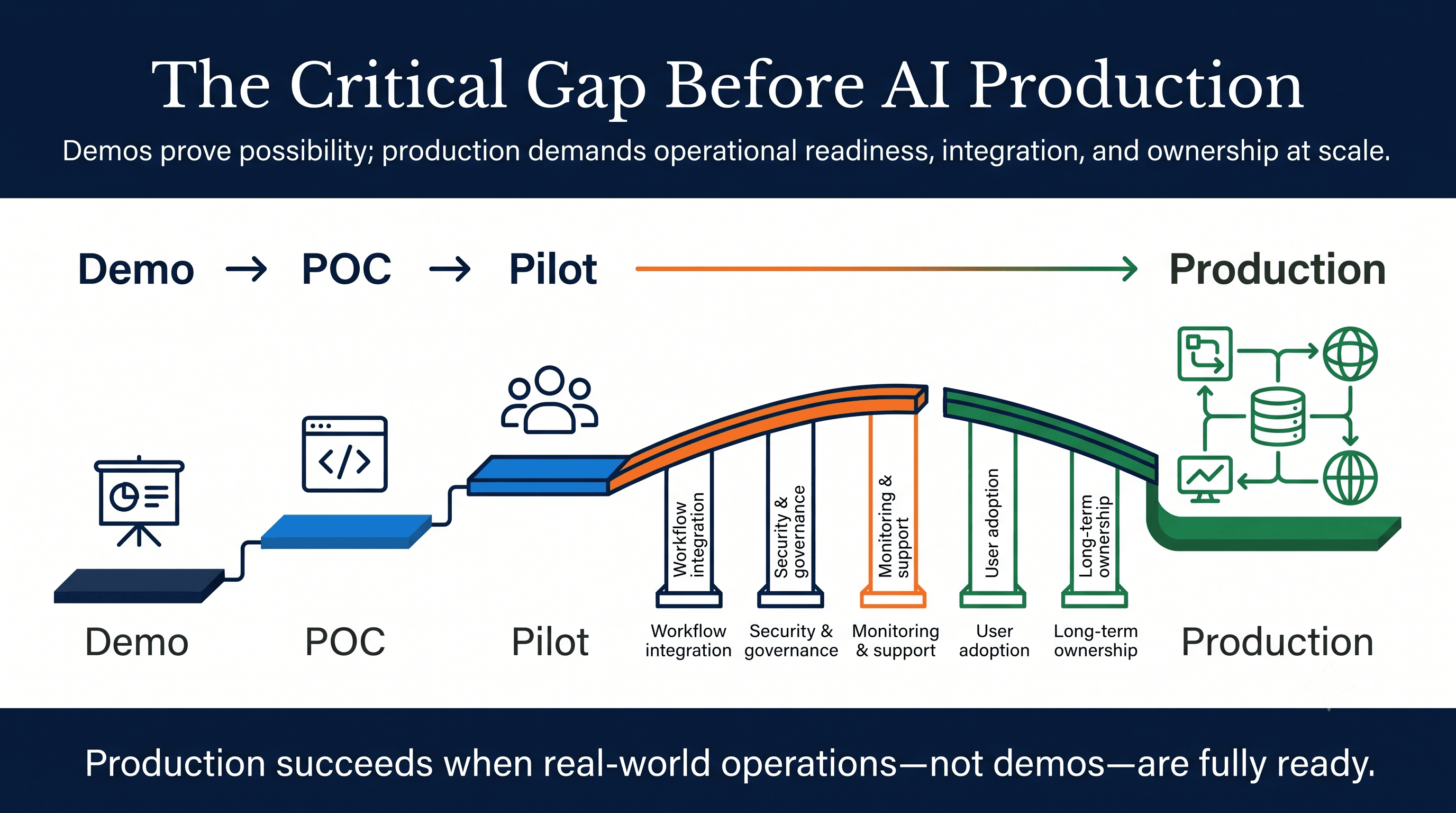
The four states vendors blur together: demo, proof of concept, pilot, and production
A demo shows what a capability can look like under controlled conditions. It may use curated data, scripted flows, or a narrow success path.
A proof of concept (POC) tests whether a bounded technical idea can work. The goal is feasibility, not operational readiness.
A pilot introduces the system to a limited real-world setting. It may use live or near-live data and a small user group, but it is still controlled, time-boxed, and not yet business-as-usual.
Production deployment is different. It means full or intended user access, live data under governance, workflow integration, monitoring, support, change management, and long-term ownership.
The gap between pilot and production is where many AI initiatives fail. Integration, security review, monitoring, user adoption, exception handling, and maintenance rarely show up in a glossy demo.
A shipped AI system has owners, users, controls, and consequences
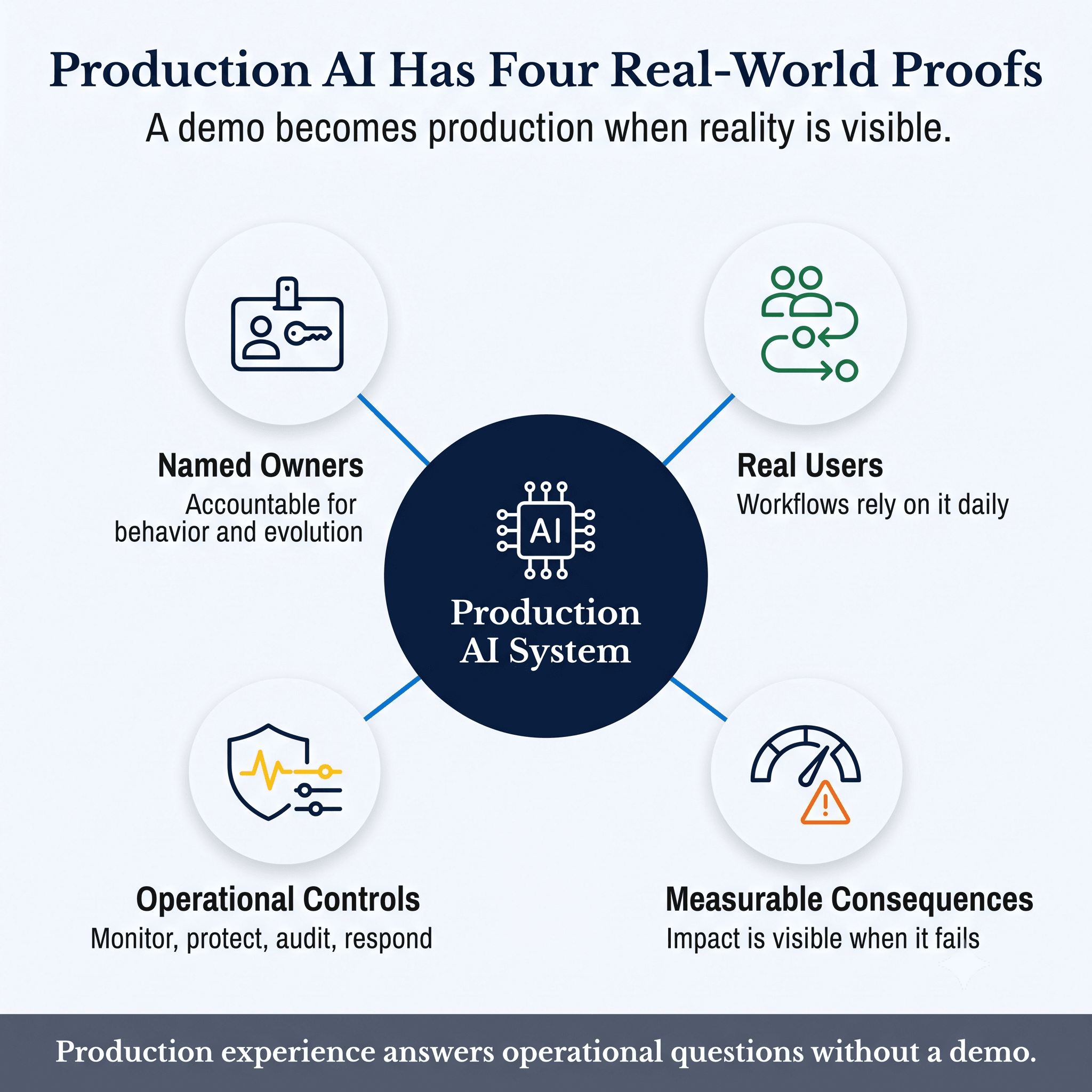
A production AI system has four visible traits.
Owners: named people accountable for system behavior, support, and evolution.
Users: real business users whose workflows depend on the system.
Controls: monitoring, access control, audit logging, incident response, and change management.
Consequences: measurable operational impact when the system works, and real disruption when it fails.
Ask a vendor to name the current system owner for a claimed production deployment. Ask how many users rely on it. Ask what gets monitored and who receives alerts. Ask what happened during the last production incident.
A vendor with production experience can answer without turning the conversation back into a demo.
Build the production track record screen before the first sales call
Most selection processes begin with a demo. That rewards the wrong skill.
A better sequence is simple: ask for production evidence first, then decide whether the vendor earns discovery time.
This is not an unreasonable procurement demand. Vendors that have shipped understand the request. Vendors that mostly sell pilots often respond with case study PDFs, broad claims, or confidentiality objections that avoid every specific question.
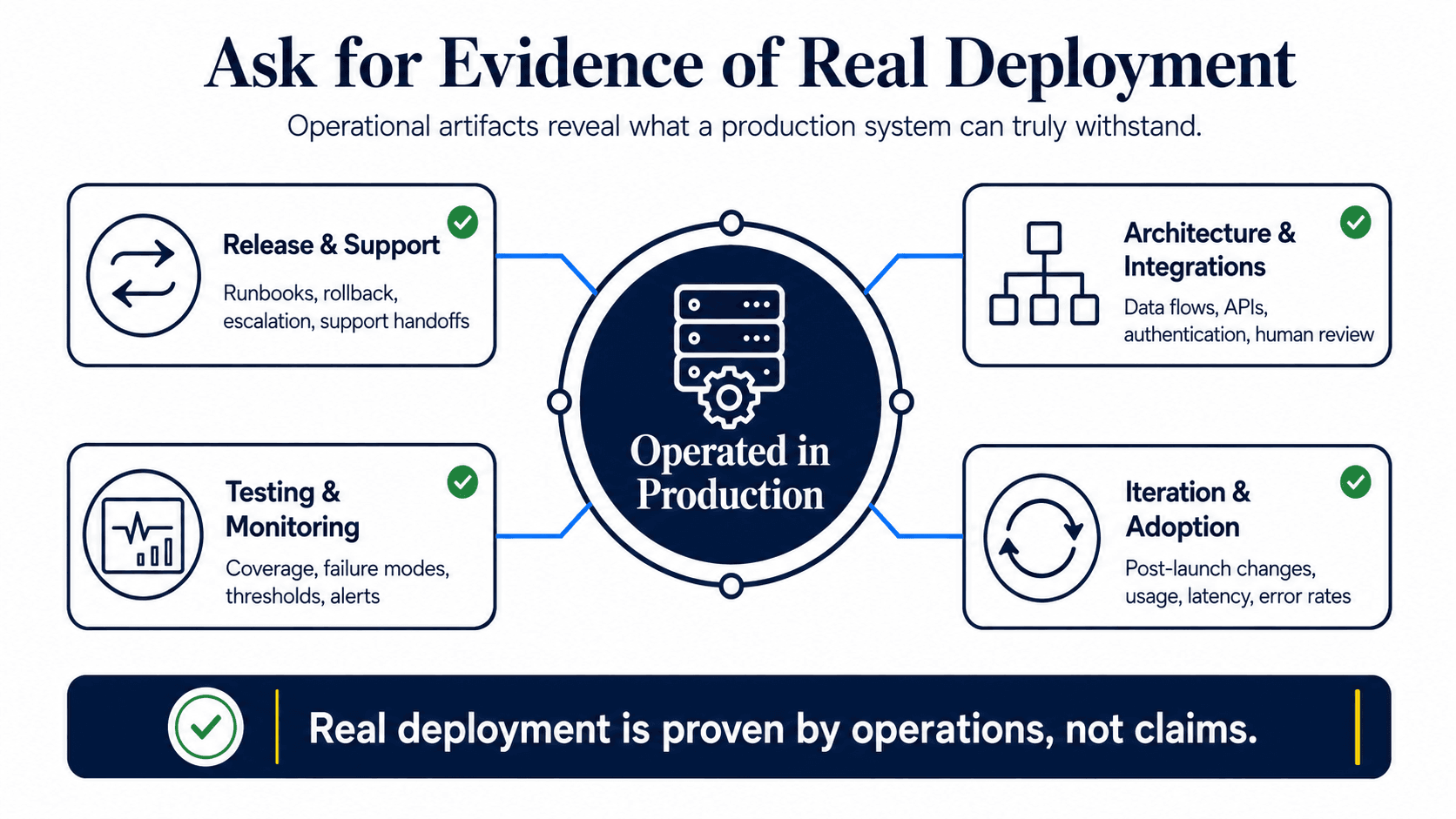
Artifacts that prove real deployment better than a case study headline
Ask for anonymized artifacts from recent production deployments. The vendor may need to remove client names, data fields, diagrams, or security details, but they should still be able to show the shape of real operational work.
Strong evidence includes:
- Deployment runbooks covering release, rollback, escalation, and support procedures
- Architecture diagrams showing data flows, integrations, AI components, and monitoring
- Integration maps showing authentication, enterprise systems, APIs, and human review points
- Evaluation summaries showing task categories, test coverage, failure modes, and release gates
- Monitoring dashboard examples or descriptions of signals, thresholds, and alerts
- Incident response procedures or redacted post-incident summaries
- Post-launch iteration logs showing prompt, retrieval, model, or workflow changes
- Support handoff documents and training records for the buyer's internal team
- Anonymized production metrics, such as usage volume, latency, error rates, or adoption
The phrasing matters: "Share what you can without client-identifying details. We are looking for evidence that the system was operated, not private data."
Questions that expose who owned the hard parts after launch
The fastest way to test production maturity is to ask operational questions.
Use these in the first serious vendor conversation:
- "Walk us through monitoring on your most recent production deployment. What signals did you track?"
- "Describe a data quality or pipeline issue after launch. How was it detected and resolved?"
- "Who owned incident response, and what was the escalation path?"
- "How did user feedback change the system after launch?"
- "What regression tests ran before updates went live?"
- "Who owned the system after your main engagement ended?"
- "What did your team document so the client could operate the system without you?"
Strong answers include specific roles, examples, timelines, and artifacts. Weak answers sound hypothetical: "We would normally..." or "The client handled that."
A vendor may intentionally hand off operations to the buyer. That is acceptable only if the handoff is evidenced through training, documentation, support terms, and references from the team that inherited the system.
Minimum acceptable proof changes with project risk
Do not apply one proof standard to every AI project.
For an internal knowledge assistant, you may accept lighter evidence: a couple of production references, a basic monitoring description, and a clear data boundary.
For a customer-facing workflow, require stronger proof: post-launch owner references, evaluation summaries, incident response documentation, and security review evidence.
For regulated data workflows or revenue-critical automation, the bar should be higher still: formal evaluation evidence, monitoring and escalation paths, security documentation, explicit acceptance criteria, and proof of post-launch support.
The higher the consequence of failure, the less patience you should have for demo-only evidence.
Use eval evidence as a gate, not a pitch-deck accessory
Evaluation evidence is one of the clearest differences between pilot vendors and production vendors.
A serious AI vendor does not treat evaluation suite coverage as a one-time launch formality. They test behavior before release, monitor behavior after release, and use failure patterns to improve the system. That is especially important for large language model applications, retrieval augmented generation systems, and agentic workflows where production inputs may diverge from test conditions.
What a serious vendor can show without revealing client secrets
A vendor does not need to expose private client data to show evaluation maturity.
They can share:
- Evaluation categories, such as task success, factuality, retrieval quality, latency, safety, and regression performance
- Test set structure, including edge cases and failure coverage
- Failure taxonomy, such as hallucination patterns, retrieval errors, drift, or policy violations
- Human review process, including who reviews outputs and how often
- Release gates, including what must pass before updates reach production
- Monitoring feedback loops, showing how production findings change the system
Be cautious with accuracy claims that lack definitions. "95 percent accurate" means little unless the vendor explains the task, test set, sample size, threshold, and measurement method.
References and case studies only count when they point to live systems
A case study is marketing evidence. A production reference is operational evidence.
Both can be useful, but only one tells you whether the system still works after the announcement.
Use case studies to understand the story. Use references to verify the system.
Ask for the reference that inherited the system six months later
The most useful reference is rarely the executive sponsor. Ask for the person who inherited operational responsibility after launch: the product owner, platform owner, operations lead, or business user who has lived with the system.
Ask them:
- "Is the system still running?"
- "What broke after launch?"
- "How much effort does your team spend maintaining it?"
- "Did the vendor support you after the initial deployment?"
- "What would you ask differently before signing again?"
A vendor that can only produce sales-friendly sponsors may still have satisfied customers. But they have not yet proven production durability.
Verify whether the case study is current, live, and material
A case study may describe a system that launched, stalled, or was replaced.
Ask whether the system is currently active, how many users rely on it, when it was last updated, and what measurable workflow outcome it supports.
Material production work has operational weight. It affects processing time, ticket volume, compliance review, customer experience, revenue workflows, or internal productivity. A screenshot and a launch quote are not enough.
Spot the pilot-agency pattern before it reaches the statement of work
The pilot-agency pattern appears before delivery begins. It shows up in scope, ownership, evidence, and contract language.
This is where buyers should slow down. Once the statement of work is signed, vague production responsibility becomes expensive ambiguity.
The contract language that keeps a vendor safely in demo mode
A statement of work can quietly cap the engagement at prototype quality.
Watch for these patterns:
- Deliverables defined as "prototype," "proof of concept," or "demonstration"
- No service level agreement for post-launch support
- Acceptance criteria such as "acceptable accuracy" without measurement details
- No owner for integrations with data systems, APIs, authentication, or workflow tools
- No monitoring, alerting, observability, or incident response requirements
- No knowledge transfer, documentation, or internal team training
You do not need to prescribe every tool the vendor must use. You do need production obligations in plain terms: what must work, how it will be measured, who owns it, and what happens when it fails.
Wrapper risk is not about the interface. It is about who owns the system behavior
A wrapper is not automatically bad. Many durable AI systems use foundation model APIs.
The risk appears when the vendor has little beyond a prompt, a user interface, and generic model access. A thin wrapper may look impressive until pricing changes, model behavior shifts, data quality degrades, or production users expose edge cases.
Ask what the vendor owns beyond the foundation model: retrieval logic, data integration, evaluation, orchestration, monitoring, governance, or domain-specific workflows.
The issue is not whether the system uses a large language model. The issue is whether the vendor can explain, measure, operate, and improve the system's behavior.
Score vendors on production behavior, not AI vocabulary
By the final selection stage, the strongest vendor should not be the one with the most fluent AI vocabulary. It should be the one with the best production evidence.
Use a simple scorecard to force the discussion back to artifacts.
A practical production-readiness scorecard
Score each category from 0 to 3.
0 means no evidence. 1 means a claim without verification. 3 means specific evidence, artifacts, or reference confirmation. Avoid false precision. The point is to separate proof from narrative.
Criterion | What earns a strong score | Weight |
Live deployment proof | Current production references and operational artifacts from past deployments | 30% |
Integration depth | Real integration maps and examples of enterprise system connections | 15% |
Eval discipline | Evaluation summaries, failure taxonomy, regression tests, and release gates | 15% |
Monitoring and incident response | Specific signals, thresholds, escalation paths, and incident examples | 15% |
Security posture | Relevant documentation, security review process, and AI-specific risk controls | 10% |
Reference quality | Post-launch operational owners who can discuss real system behavior | 10% |
Post-launch ownership | Handoff plan, support terms, training, and knowledge transfer | 5% |
A vendor weak on live deployment proof should not be rescued by a strong demo. That category carries the most weight because it is the hardest to fake.
Disqualifiers that should stop the process early
Some signals should end the evaluation before scoring continues:
- The vendor cannot define production clearly.
- They cannot provide a live production reference.
- They refuse to discuss evaluation methods.
- Their evidence is limited to demos, decks, and case studies.
- Their statement of work has no post-launch ownership.
- Their security posture is vague for a sensitive use case.
- They cannot identify who owns the deployed system today.
Treat these as hard stops for high-risk work. A vendor can be skilled at prototypes and still be the wrong partner for production.
Tie-breakers when two vendors both look credible
When two vendors pass the production screen, use tie-breakers tied to your operating context.
Domain fit matters when workflows, regulations, or data constraints are specific, a place where the choice between boutique and larger firms often comes into focus. Architecture transparency matters when you need long-term control. Internal team enablement matters if your goal is to build capability, not vendor dependency.
Governance maturity matters for sensitive data. Cost visibility matters when monitoring, retraining, support, and infrastructure will continue after launch. A willingness to define measurable production milestones matters because it turns promises into a go/no-go structure.
The better vendor is the one that leaves you with a stronger operating model, not just a working first version.
The twelve percent are easier to find when the first conversation is about operations
The market's pilot problem is not just a technology issue. It is an evaluation issue.
Buyers invite demo-first behavior when they begin with broad capability questions. They invite production evidence when they ask about operations first.
A practical first sequence looks like this:
- Ask for anonymized production artifacts before the demo.
- Require at least one reference from a post-launch operational owner.
- Ask how the last production system was monitored.
- Ask what broke after launch and how it was handled.
- Review the statement of work for monitoring, acceptance criteria, handoff, and support.
- Apply disqualifiers before the vendor reaches final scoring.
The 88 percent figure should not be used as a direct claim about vendors. It is better understood as a warning about the environment vendors sell into: most AI initiatives struggle to cross the production gap.
The twelve percent are the vendors that can talk about that gap without hiding behind a demo. They can show artifacts. They can name owners. They can explain incidents. They can describe evals. They can connect production claims to live systems.
That is the standard worth buying against.
For the rest of the workflow, return to the complete AI engineering partner selection guide.
Frequently Asked Questions
Q: What does the 88% AI pilot failure stat actually mean?
A: It means 88% of AI proofs of concept never reach widescale deployment, according to IDC and Lenovo. That works out to about four production deployments for every 33 POCs, and it describes the market, not a vendor census.
Q: What counts as a production AI system versus a pilot?
A: Production means the system is integrated into real workflows, used by real users, monitored under live conditions, and owned by named people after launch. A pilot is still controlled, time-boxed, and run with a small user group.
Q: How do I screen an AI vendor before the sales demo?
A: Ask for anonymized production artifacts first, then decide if the vendor earns discovery time. Starting with a demo rewards the wrong skill and lets the vendor define what "shipped" means.
Q: What artifacts prove an AI vendor has shipped real systems?
A: Deployment runbooks, architecture diagrams, integration maps, evaluation summaries, monitoring dashboards, and incident response procedures all prove real operational work. Vendors can strip client names and still show the shape of the work.
Q: What questions expose whether a vendor owned the hard parts after launch?
A: Ask who owned incident response, what broke after launch, and what regression tests ran before updates went live. Strong answers name specific roles, timelines, and artifacts.
Q: Why should I talk to the person who inherited the system, not the sponsor?
A: The operational owner knows whether the system still runs and what maintenance it takes. The executive sponsor gives you a sales-friendly story, not proof of durability.
Q: What contract language traps a vendor in demo mode?
A: Deliverables labeled "prototype" or "proof of concept," no post-launch support SLA, and acceptance criteria like "acceptable accuracy" with no measurement. Missing owners for integrations and monitoring are also red flags.
Q: Is a thin wrapper on a foundation model a bad sign?
A: A wrapper is fine if the vendor owns retrieval, data integration, evaluation, monitoring, and governance around it. The risk is when they have little beyond a prompt, a UI, and generic model access.
Just published



