Trusted by Market Leaders in Education, Travel, Finance and E-commerce since 2007





We put excellence, value and quality above all - and it shows






A Technology Partnership That Goes Beyond Code

“Arbisoft has been my most trusted technology partner for now over 15 years. Arbisoft has very unique methods of recruiting and training, and the results demonstrate that. They have great teams, great positive attitudes and great communication.”










Micro-Partitions: The Hidden Engine Behind Snowflake's Performance Advantage


In the world of cloud data warehousing, Snowflake stands out for its impressive speed, scalability, and smart resource management. Sure, the intuitive interface and pay-as-you-go pricing get a lot of attention, but if you ask me, the real game-changer is tucked away in its core architecture: micro-partitions. These are what give Snowflake a genuine edge over traditional databases and even some other cloud players. In this blog, I'll break down what they are, how they work, and why they matter so much. If you're in data engineering, analytics, or IT strategy, this could shift how you think about handling big data sets.
The Basics of Data Partitioning
Partitioning data is one of those fundamental ideas in databases. It is essentially about breaking up huge tables into smaller pieces to make queries run smoother. I like to compare it to sorting a massive library: instead of hunting through every shelf for a book, you group them by category so you can zero in faster.
In older systems, like Hadoop-based ones or classic relational databases, partitioning is pretty rigid. They slice data into big chunks based on rules like dates or keys. It helps, but it's not perfect. If your query doesn't match those rules exactly, you're still sifting through a ton of extra data, which slows everything down. That is where Snowflake steps in with micro-partitions, offering a fresher, more flexible take that avoids those headaches.
What Exactly Are Micro-Partitions?
At their core, micro-partitions are tiny, fixed chunks of data, usually 50–500 MB each, that Snowflake creates automatically when you load your data. It's not haphazard; the system clusters similar values together based on how the data comes in, which keeps things organized without you lifting a finger.
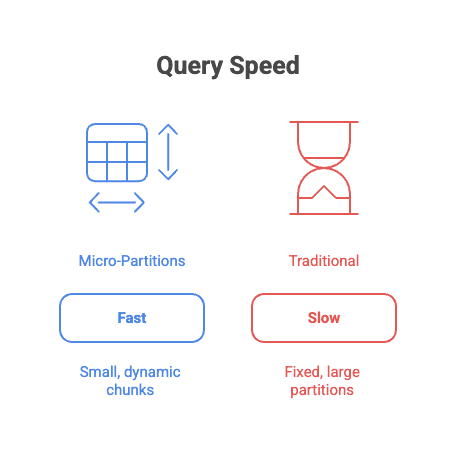
What really sets them apart, though, is the metadata attached to each one. Think of it as a quick summary card: it lists things like the min and max values, how many rows are inside, and even some stats on data spread. When you fire off a query, Snowflake's optimizer just glances at these cards and skips the partitions that don't match. No unnecessary digging. It prunes the junk right away, making queries fly.
That image really drives the point home, doesn't it? It shows how micro-partitions make data access so much more targeted.
How They Drive Better Performance
From my experience working with these systems, micro-partitions shine in a few key areas. For starters, there is automatic clustering. Snowflake quietly reorganizes things in the background, keeping data grouped efficiently as it evolves. No more manual tweaks like in older setups. That is a huge time-saver.
Then there is the parallel processing boost. Since the partitions are small and standalone, Snowflake can spread queries across its virtual warehouses effortlessly. Ramp up compute for a big job, and each node grabs its own set of partitions. It is scalable in a way that feels almost effortless.
They also tie in nicely with features like time travel and zero-copy cloning. The partitions are immutable, so you can peek at past data versions or clone tables just by updating metadata. There is no copying of files around and bloating your storage bill.
I have seen this in action with teams I have consulted for. Queries that dragged on for minutes in legacy systems now wrap up in seconds. It is not hype; it is the pruning and parallelism paying off.
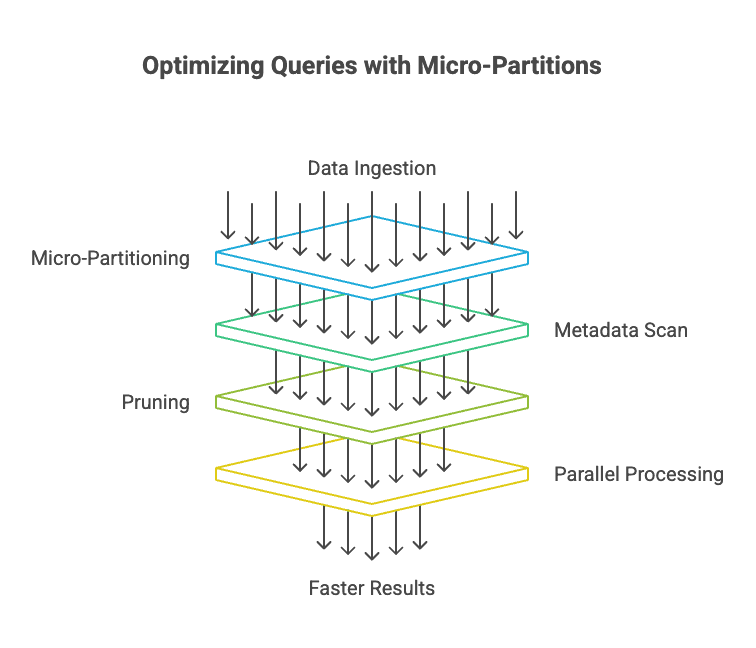
This flowchart lays out the process step by step; it's a great way to see the efficiency in motion.
What Sets Snowflake Apart from the Rest
Competitors like BigQuery and Redshift have their strengths. BigQuery's columnar storage is solid for analytics, and Redshift's sort keys can optimize things nicely. But Snowflake's micro-partitions go a step further with their automation and rich metadata. You do not have to constantly fiddle with indexes or repartition when your data shifts, which is a common pain point elsewhere.
Benchmarks and technical analyses demonstrate that Snowflake’s architectural design, particularly its storage-compute separation and use of micro-partitions, enables highly efficient query execution. For example, advanced partition-pruning techniques have been shown to reduce the number of processed micro-partitions by up to 99.4%, drastically cutting the data scanned and speeding queries (arXiv, 2025).
This efficiency stems from how Snowflake keeps detailed metadata about micro-partitions in cheap cloud storage, while compute nodes scale independently. This delivers flexibility, especially across multi-cloud environments (AWS, Azure, GCP).
Where They Make a Real Difference
In the field, micro-partitions really prove their worth with high-volume, unpredictable queries. Take a retail company crunching sales data during peak seasons. They can prune away irrelevant dates or products in a flash. Or in healthcare, where compliance is key, the metadata helps you access just what is needed without touching sensitive extras.
They handle those spur-of-the-moment analytics workloads without skipping a beat, which is something I have appreciated in my own projects.
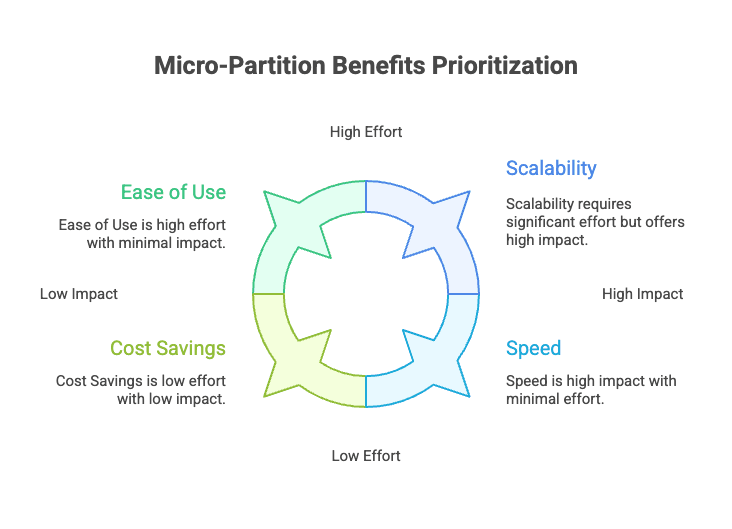
This one captures the perks at a glance. It is handy for quick reference.
Final Thoughts: Why This Matters to You
At the end of the day, micro-partitions are what make Snowflake's performance feel like a well-oiled machine. They provide smart data handling through metadata and automation that just works without constant oversight. If you are dealing with growing data demands, whether it is exploding volumes from IoT sensors or complex analytics in a fast-paced business, they are worth a closer look for the efficiency gains alone. They do not just speed things up; they free your team from the drudgery of manual optimizations, letting you focus on insights that actually drive decisions. In my view, that is the real win: turning data from a bottleneck into a strategic asset.
Just published



