Trusted by Market Leaders in Education, Travel, Finance and E-commerce since 2007





We put excellence, value and quality above all - and it shows






A Technology Partnership That Goes Beyond Code

“Arbisoft has been my most trusted technology partner for now over 15 years. Arbisoft has very unique methods of recruiting and training, and the results demonstrate that. They have great teams, great positive attitudes and great communication.”











Custom Software Development Engagement Models Guide (US Buyers)


US buyers often pick a software development engagement model based on the headline: fixed scope sounds “safe,” dedicated team sounds “agile,” and staff augmentation sounds “flexible.” The real decision is about ownership, governance, and how change and risk are handled. This engagement model selection framework helps when vendor proposals sound “in between.”
If you want the full end-to-end selection flow (beyond just engagement models), start with the buyer’s guide to choose a custom software development partner.
Action: Write down your top constraint (scope stability, ownership bandwidth, budget behavior, risk posture) before comparing models.
Why this decision matters for US buyers
Engagement model mistakes usually show up as:
- Cost surprises that are really change-control surprises
- Schedule slips that are really dependency and decision-bottleneck problems
- Quality and security gaps that are really unclear responsibilities
A model is “right” when it matches your real constraints on:
- Clarity: how well you can define outcomes and acceptance criteria up front
- Ownership: who steers day-to-day priorities and decisions
- Risk allocation: who carries delivery, quality, and timeline risk
- Budget behavior: how much variability you can tolerate
Action: Identify who will own prioritization and acceptance on your side (name the role).
The three custom software development engagement models
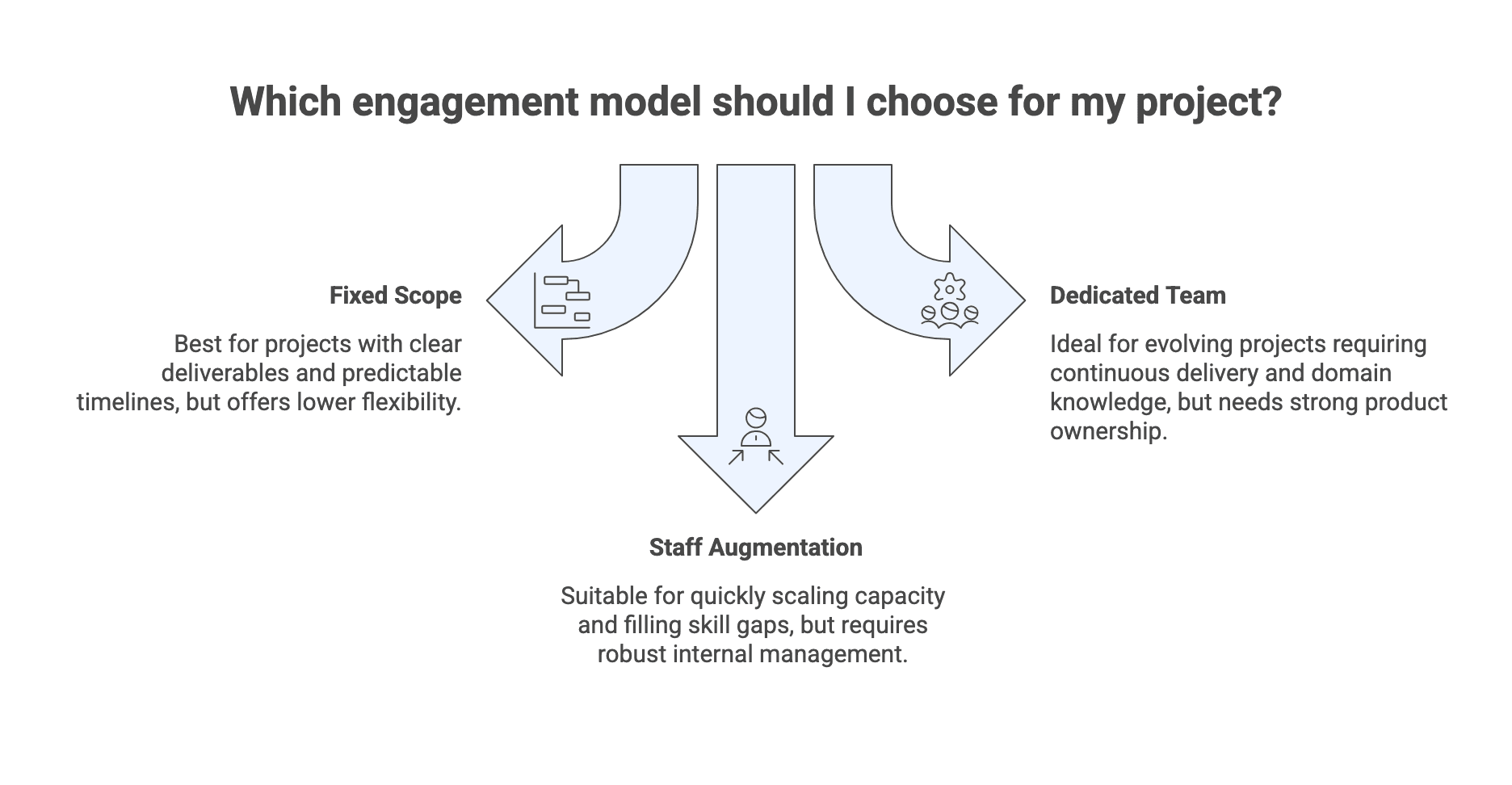
Fixed scope (project-based)
What you are buying: a defined set of deliverables for a defined price and timeline, typically documented in a Statement of Work (SOW).
How it works:
- Requirements are expected to be stable enough to specify up front.
- Any change becomes a formal change request (CR) that can affect cost and schedule.
- Success depends heavily on upfront clarity, including non-functional requirements (NFRs) like performance, reliability, and security expectations.
Best fit when:
- You can define “done” clearly (testable acceptance criteria).
- You can tolerate lower flexibility in exchange for predictability.
- The work is bounded (for example: a well-scoped module, integration, or migration with clear constraints).
Typical failure mode: shallow discovery leads to missing dependencies, then CR churn and disputes over acceptance.
Action: If you want fixed scope, require a discovery output that makes acceptance criteria testable.
Dedicated team
What you are buying: a stable “managed capacity” team (a long-lived squad) that continuously delivers, usually on a time and materials (T&M) basis with a steady cadence.
How it works:
- You are not buying a single deliverable, you are buying throughput over time.
- Success requires strong product ownership, backlog readiness, and clear decision rights.
- Governance matters: teams can be “busy but not effective” if priorities and outcomes are unclear.
Best fit when:
- The product scope will evolve and you expect learning and iteration.
- You can provide a strong product owner and fast decisions.
- You want continuity and accumulated domain knowledge.
Typical failure mode: “team on standby” waste caused by slow decisions, unrefined backlog items, or external blockers.
Action: If you want a dedicated team, confirm you can keep a backlog ready at least one to two sprints ahead.
Staff augmentation
What you are buying: additional individuals (or specialists) who join your team and operate under your management and standards.
How it works:
- Ownership stays with you: priorities, code review standards, and delivery management are yours.
- It can scale capacity quickly and fill niche skill gaps.
- The risk rises if onboarding, access, and standards are weak, or if internal leadership bandwidth is limited.
Best fit when:
- You have an internal engineering manager and delivery system that can absorb more people.
- You need specific expertise (short-term or targeted) without changing your operating model.
- You need flexibility to scale up or down by role.
Typical failure mode: integration breakdown (access gaps, unclear ownership, inconsistent engineering practices), amplified by time-zone friction and culture mismatch.
Action: If you want staff augmentation, ensure your onboarding plan and engineering standards are documented before you add people.
Options compared: fixed scope vs dedicated team vs staff augmentation
Summary of differences (buyer terms)
Use this table as a first-pass filter. Then validate with the verification artifacts later in this guide.
Dimension | Fixed scope | Dedicated team | Staff augmentation |
| Scope and change | Scope is defined up front; changes go through CRs | Scope evolves via backlog reprioritization | Scope evolves via your internal planning |
| Ownership | Vendor commits to defined deliverables; buyer must define “done” | Shared delivery mechanics; buyer must steer priorities | Buyer owns day-to-day delivery and acceptance |
| Governance load | Higher upfront specification; more formal change control | Ongoing cadence (Agile ceremonies, reporting, decision rights) | Your existing governance must scale with added people |
| Cost behavior | Predictability improves with clarity; variance shows up as CRs | Spend aligns to team capacity over time | Spend aligns to roles added; value depends on integration |
| Best-fit pattern | Bounded work with stable requirements | Product evolution with strong product ownership | Scaling internal delivery with added skills |
| Common failure | Ambiguous acceptance and hidden dependencies | Weak product ownership or “standby” waste | Weak onboarding and inconsistent standards |
How to read it: fixed scope shifts risk into definition and change control, dedicated team shifts risk into governance and product ownership, and staff augmentation shifts risk into integration and management capacity.
Action: Pick the model whose “common failure” you are most equipped to prevent.
Decision criteria (what matters most)
The fastest way to decide on how to choose a custom software development engagement model is to answer these questions honestly:
- Who owns the backlog and prioritization?
- Who has the authority to accept or reject work?
- How will scope or priorities change (CRs vs backlog trade-offs)?
- What happens if key people roll off (replacement time, continuity expectations)?
If a vendor proposal feels “in between,” these questions usually reveal what you are actually buying: a project, managed capacity, or extra hands under your management.
Action: Ask each vendor these four questions and document their answers verbatim.
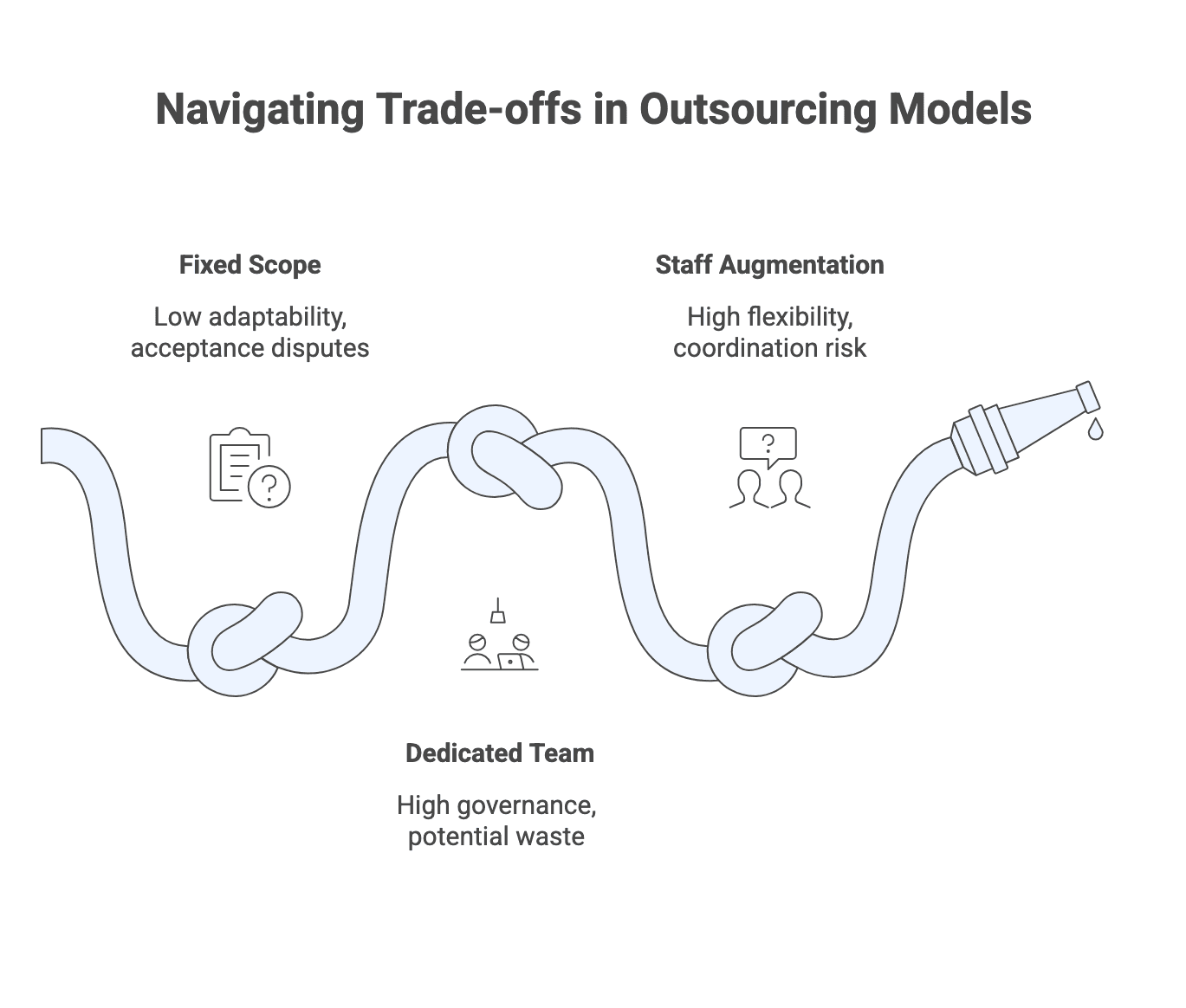
Trade-offs and failure modes of engagement models
Fixed scope trade-offs:
- Stronger predictability when the scope is truly stable
- Lower adaptability when requirements evolve
- Disputes tend to cluster around acceptance criteria and CR pricing
Dedicated team trade-offs:
- Higher adaptability and learning over time
- More ongoing governance and decision-making demand
- Waste appears when the team is blocked by ownership or dependencies
Staff augmentation trade-offs:
- Maximum flexibility in scaling specific skills
- Management burden stays with you only
- Coordination and quality risk rises if leadership bandwidth and standards are thin
Action: Decide whether your biggest risk is scope volatility, governance bandwidth, or integration overhead.
Recommendation logic (scenario-based)
Here is a quick scenario-to-model mapping you can use to shortlist:
- You have stable requirements, clear acceptance tests, and a bounded outcome: start with fixed scope.
- You have a product roadmap that will evolve and you can provide a strong product owner: start with a dedicated team.
- You have an existing engineering system and need extra capacity or niche skills: start with staff augmentation.
- You are unsure about volatility or collaboration fit: run a pilot first, then decide (you can switch models after learning).
- You expect a lifecycle pattern: many teams use fixed discovery, then dedicated build-out, then lean staff augmentation for targeted maintenance or enhancements.
Action: Shortlist two models, and define what would disqualify each one.
What to evaluate before you choose a software development engagement model
Scope clarity and requirements volatility
Signals you can use:
- Do you have testable acceptance criteria, or only feature descriptions?
- Are dependencies known (integrations, third-party systems, stakeholder availability)?
- Are NFRs explicit (performance, security, uptime, data handling)?
Fixed scope requires the strongest up-front clarity. Dedicated teams tolerate discovery and change better, but still need a well-run backlog. Staff augmentation assumes you can translate scope into executable work internally.
Action: Write down your top three unknowns and decide whether you need a discovery sprint before committing.
Ownership and governance capacity
All models need governance, but the burden shifts:
- Fixed scope needs crisp change control and clear acceptance authority.
- Dedicated teams need ongoing ceremonies, decision rights, escalation paths, and a ready backlog.
- Staff augmentation needs internal engineering leadership and standards that scale.
If decisions are slow or ownership is split across many stakeholders, dedicated team and staff augmentation risk “busy but not effective” outcomes.
Action: Name the product owner and define decision rights (who can approve scope, accept work, and resolve disputes).
Budget behavior: predictability vs adaptability
Instead of asking “Which model is cheaper?” ask:
- How much variance can we tolerate if scope changes?
- Are we funding a defined deliverable (fixed) or capacity over time (dedicated, staff aug)?
- Can we put guardrails in place (caps, checkpoints, and clear change mechanics)?
Fixed scope optimizes for predictable outcomes when clarity is high, but changes are handled through CRs. Dedicated team and staff augmentation behave more like capacity spend where value depends on governance and prioritization.
Action: Decide whether Finance needs a fixed outcome price or can approve a capacity budget with checkpoints.
Talent needs: skills, seniority, continuity
Use the work profile to choose:
- If continuity and domain knowledge matter, dedicated team is often strongest.
- If you need specialists (short-term), staff augmentation can be efficient.
- If work is bounded and can be specified, fixed scope can work if you can define quality expectations.
Turnover risk matters in all models. Ask how replacements work and what continuity mechanisms exist.
Action: List the two most critical roles and define what “acceptable replacement” means (seniority, ramp time, and overlap expectations).
Risk allocation: quality, security, and timelines
Quality responsibilities should be explicit: who designs tests, who runs them, and what standards apply for code review, continuous integration/continuous delivery (CI/CD), and defect resolution. Security responsibilities should be explicit: access control, data handling, and adherence to internal policies or regulations.
Timeline risk often comes from dependencies and decision bottlenecks more than raw development speed, so governance and clarity matter as much as headcount.
One-page decision rubric:
- Scope stability: Low / Medium / High
- Ownership bandwidth (product + engineering): Low / Medium / High
- Budget flexibility: Low / Medium / High
- Integration and dependency complexity: Low / Medium / High
- Security and compliance sensitivity: Low / Medium / High
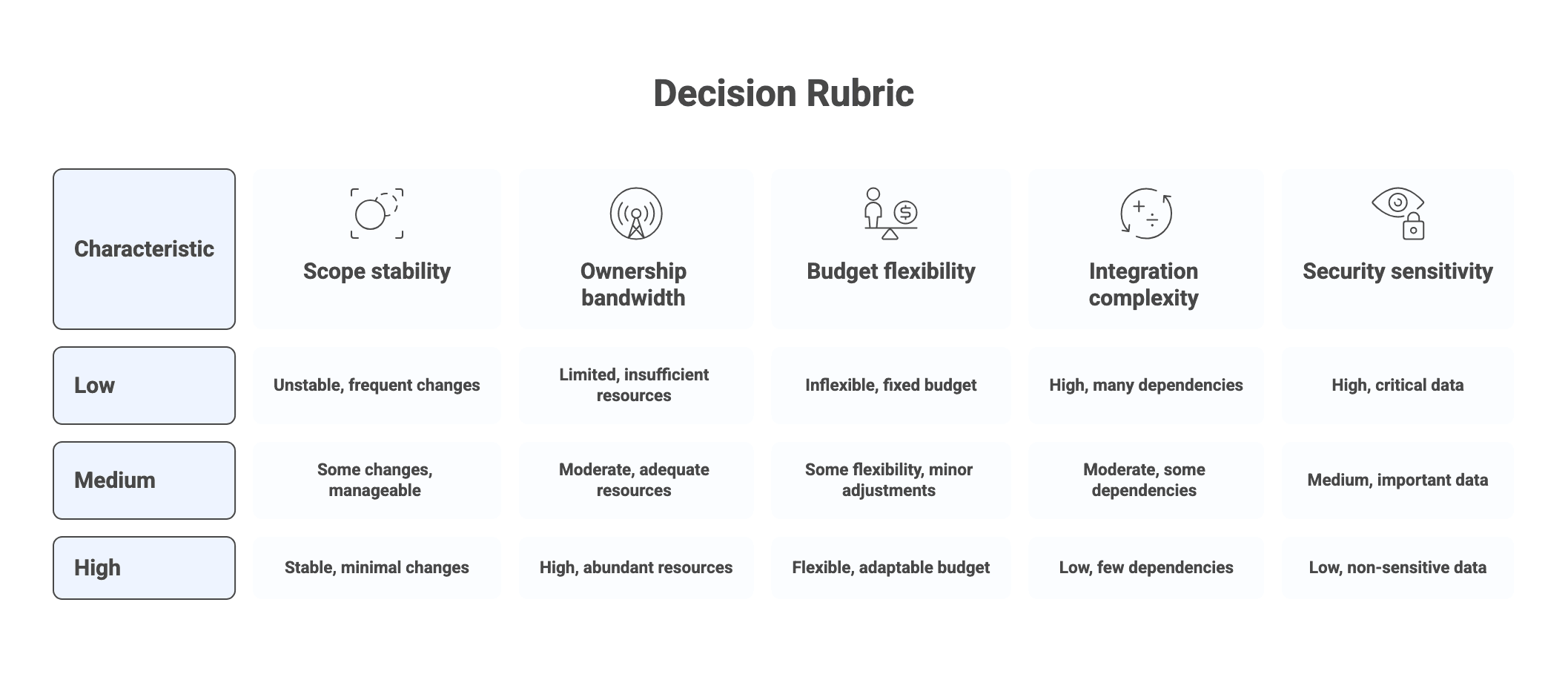
Interpretation:
- If scope stability is High and budget flexibility is Low, favor fixed scope.
- If scope stability is Low and ownership bandwidth is High, favor dedicated team.
- If ownership bandwidth is High (especially engineering management) and you need flexible scaling, favor staff augmentation.
- If multiple inputs are unknown, run a pilot before locking the model.
Action: Fill the rubric with your stakeholders in one meeting and align on the top constraint.
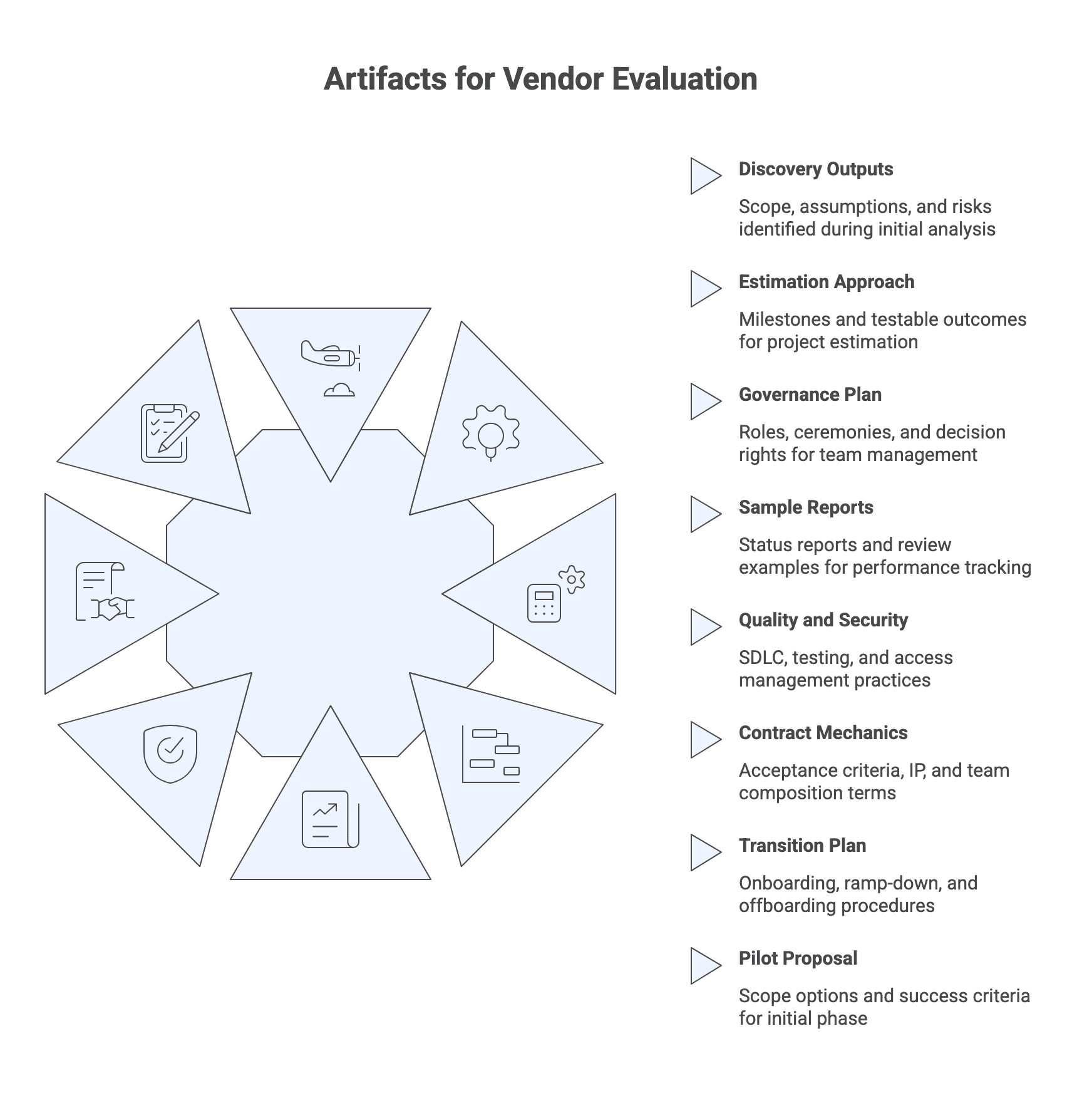
Practical verification steps and artifacts to request
Before committing to any model, validate reality through concrete artifacts and low-risk tests. Evidence that a supplier can deliver includes robust estimates with assumptions and risks, documented governance, sample reports, and a clear approach to ramp-up and ramp-down.
Artifact request list (bring to vendor calls):
- Discovery outputs (scope, assumptions register, risks list)
- Estimation approach and milestone definitions tied to testable outcomes
- Governance plan (roles, ceremonies, decision rights, escalation)
- Sample status reports or dashboards and sprint or milestone review examples
- Quality and security artifacts (SDLC overview, testing strategy, code review practices, access management)
- Contract mechanics (acceptance criteria, CR process, IP and confidentiality basics, team composition terms)
- Transition plan (onboarding, ramp-down, offboarding checklist)
- Pilot proposal (scope options and success criteria)
Action: Request these artifacts before final pricing discussions.
Discovery and estimation: what to request and how to sanity-check it
Estimation methods vary (analogous, bottom-up by work item, hybrid).
Regardless of technique, insist on explicit assumptions about:
- Technology choices and environments
- Performance expectations and NFRs
- Integration complexity and dependency availability
- Stakeholder availability (reviews, approvals, data access)
Sanity checks that catch unrealistic estimates:
- Are milestones defined as observable, testable outcomes (not internal activities)?
- Are dependencies and NFRs included?
- Do timelines and team size pass a “similar work” plausibility test?
Action: Ask the vendor to walk you through their assumptions register and what happens if key assumptions fail.
Governance and operating model: how the team will actually run
Governance differs by model but should always define:
- Roles (product owner, delivery lead, engineering lead)
- Ceremonies (planning, reviews, retrospectives)
- Reporting (dashboards, status updates, risks/issues)
- Decision rights (scope changes, backlog priority, acceptance)
- Tooling and communication norms (issue tracking, documentation standards, channels)
Fixed scope often uses more formal stage-gate governance. Dedicated team and staff augmentation typically use Agile cadences, but the mechanics must be explicit.
Action: Ask for a sample status report and the escalation workflow from contributor to executive sponsor.
Contract and SOW essentials (summary only, then link out)
Focus on the clauses that change risk by model:
- How deliverables and acceptance criteria are defined
- How CRs are initiated and priced
- High-level IP and confidentiality provisions
- For dedicated team and staff augmentation: team composition, replacement times, ramp-down notice periods, and minimum commitments
Red flags correlated with delivery risk include vague scope, missing acceptance criteria, ambiguous IP ownership, and change clauses that let one party unilaterally adjust timelines or fees.
For clause-level depth, see custom software development contracts & governance guide.
Action: Create a clause checklist with your counsel and confirm these model-specific mechanics are addressed.
Ramp-up, ramp-down, and exit criteria
How you start and end matters as much as day-to-day delivery.
Ramp-up expectations should include:
- Onboarding plan and access/environment setup
- Working agreements on communication and decision-making
Exit criteria that reduce lock-in should include:
- Rights to source code and documentation
- Notice periods for ending or reducing the team
- Vendor obligations to support transition during wind-down
A practical offboarding checklist should cover:
- Revoking system access
- Capturing architecture and operational runbooks
- Finalizing outstanding defects
- Confirming code and infrastructure assets are under your control
Action: Ask vendors how they handle ramp-down before you sign, and require the plan in writing.
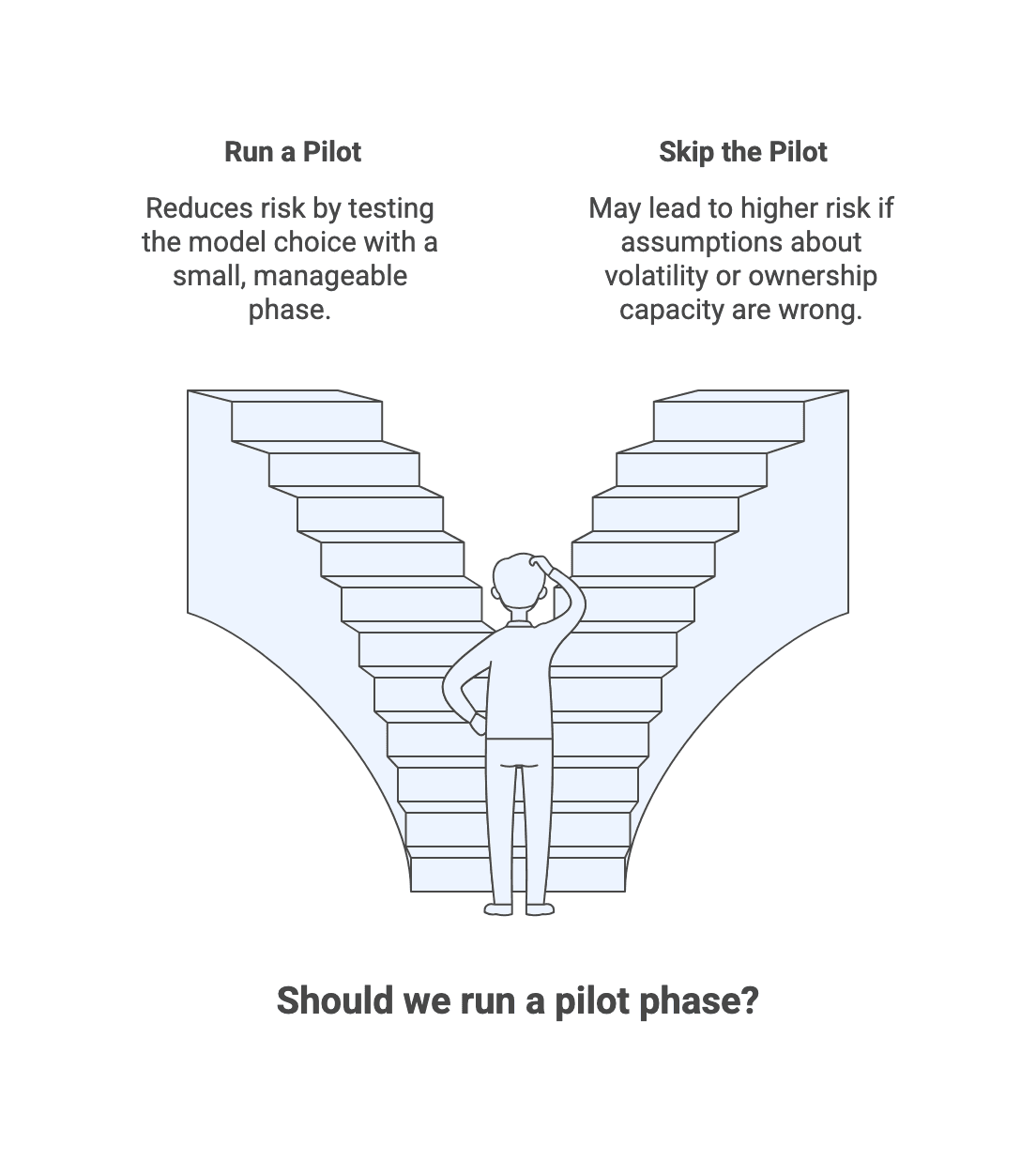
Pilot options: when a small first phase de-risks the model choice
Pilots reduce risk when uncertainty is high, the vendor is new to you, or collaboration patterns are untested.
Effective pilot scopes include:
- Discovery sprints
- Thin-slice minimum viable product (MVP) builds
- Architecture and codebase assessments
Define success criteria in advance, including:
- Communication quality and reliability of estimates
- Ability to manage change
- Fit with your internal team and governance style
After the pilot, you can continue, adjust governance or team mix, or switch models if your assumptions about volatility or ownership capacity were wrong.
Action: If you are unsure, run a pilot with explicit success criteria and a clear decision point.
Common pitfalls and how to avoid them
Red flags checklist (use during selection):
- Ownership is unclear (who prioritizes, who accepts, who decides)
- Requirements are weak and acceptance criteria are not testable
- Communication is inconsistent or overly polished without artifacts
- Quality practices are vague (no SDLC, testing strategy, code review standards)
- Metrics focus on hours burned instead of value delivered
- Estimates lack an assumptions register and a risk list
- Escalation paths and decision rights are not explicit
Plan a checkpoint two to four weeks after kickoff to confirm governance works, estimates still look realistic, and communication channels function.
Action: Decide which red flags are disqualifiers versus risks you can mitigate.
Fixed scope pitfalls
Common issues:
- Scope creep without formal change control
- Acceptance criteria that are qualitative or missing
- Hidden dependencies (integrations, third-party limitations)
Mitigations:
- Insist on a structured discovery phase
- Define acceptance criteria in testable terms
- Capture dependencies and assumptions explicitly in the SOW
- Prioritize scope so you can drop lower-priority items if constraints bite
Action: Require testable acceptance criteria and a dependency list before signing a fixed scope SOW.
Dedicated team pitfalls
Common issues:
- Weak or fragmented product ownership causes churn
- “Team on standby” waste due to slow decisions or blockers
- Misaligned incentives if success is measured only by utilization
Mitigations:
- Appoint a strong product owner
- Keep a ready backlog one to two sprints ahead
- Define outcome-oriented KPIs tied to business results
- Review whether team composition still matches your roadmap
Action: If you cannot maintain backlog readiness, do not commit to a dedicated team without a governance fix.
Staff augmentation pitfalls
Common issues:
- Weak onboarding and unclear domain context
- Inconsistent access to tools and environments
- Unclear ownership of code review and decision-making
- Standards drift that causes rework and duplication
Mitigations:
- Document development process, coding standards, and review practices
- Provide an onboarding plan (environment setup, architecture overview, domain walkthrough)
- Ensure engineering leadership bandwidth is sufficient to manage increased coordination
- Use a first-week checklist (access, codebase tour, shadowing, first small task)
Action: Do not add augmented staff until your onboarding and engineering standards are written down.
Conclusion: choose the model that matches your constraints
The most sustainable model matches your constraints on scope stability, ownership capacity, risk posture, and budget behavior.
Use a disciplined next step:
- Assemble stakeholders and complete the rubric honestly.
- Shortlist one to two viable models.
- Request artifacts (estimates, governance examples, quality and security practices, contract mechanics, transition plans).
- Run a pilot when uncertainty or collaboration risk is high.
Just published



