Trusted by Market Leaders in Education, Travel, Finance and E-commerce since 2007





We put excellence, value and quality above all - and it shows






A Technology Partnership That Goes Beyond Code

“Arbisoft has been my most trusted technology partner for now over 15 years. Arbisoft has very unique methods of recruiting and training, and the results demonstrate that. They have great teams, great positive attitudes and great communication.”











Is Claude Sonnet 4.5 the Model Engineers Have Been Waiting For?


Another quarter, another major model update. For people in tech, that flow is both thrilling and exhausting. We cheer for the new features. We test them the same day. We still worry about whether a powerful new model can actually be trusted to help carry the load of real projects.
On September 29, 2025, Anthropic released Claude Sonnet 4.5. The release asks a sharper question than usual. Can a model move from impressive demos to steady, production work? Anthropic says yes. The evidence so far makes it a milestone worth watching.
In this blog, we will explore how Sonnet 4.5 is being positioned, what it claims to do differently, and how teams can begin testing it in practice.
Is Claude Sonnet 4.5 Model Released Into Many Places?
The first thing to notice is where Sonnet 4.5 appears. Anthropic published the model on its own Claude platform and the developer API. Major cloud providers made it available as well. Amazon Bedrock listed Sonnet 4.5 as a managed model on day one. GitHub made Sonnet 4.5 available in public preview inside GitHub Copilot for eligible plans. Snowflake and Google Cloud integrations followed quickly.
This wide availability matters because teams can try the model inside the tools they already use. That lowers the barrier to real testing and adoption.
What Sonnet 4.5 Costs
That practical reach also matters for budgets. Anthropic kept Sonnet 4.5 at the same headline price as Sonnet 4. Input tokens are $3 per million and output tokens are $15 per million on the standard pricing tier. For many teams, that price is familiar and predictable. It also makes it easier to compare cost versus other models when planning pilots and production runs. Anthropic documents cost behavior for larger context use and show options to save with prompt caching and batching.
What Sonnet 4.5 Claims To Do Differently
Anthropic centers three claims in its announcement.
1. Stronger for Coding and Software Engineering
Sonnet 4.5 is stronger for coding and software engineering work.
2. Extended Autonomous Sessions
It can run extended autonomous sessions on complex tasks.
3. Better at Using Real Software
It is better at using real software, meaning it can interact with tools, files, and environments with higher reliability.
These three claims are closely connected. A model that can use tools well and keep track of what it did will naturally be more useful for building and operating software. Anthropic published technical notes that explain feature improvements and how the company evaluated them.
The most attention-grabbing claim is that Sonnet 4.5 can sustain continuous autonomous work for over 30 hours in internal trials. Anthropic and several reporters describe early enterprise runs where the model coded, stood up database services, purchased domains, and even supported some security checks during that extended period.
If you are a product manager who worries about handoffs and continuity, a tool that can maintain a task context for dozens of hours looks valuable. It’s not a blanket solution for every scenario, but it does shift what teams can realistically expect from an AI partner. Instead of constantly restarting or re-explaining tasks, teams can begin to imagine projects where the model carries the thread from start to finish.
Concrete Engineering Upgrades That Matter To Teams
Several concrete improvements make those capabilities possible. Anthropic reports better context management, a memory tool in beta, context editing features, and a larger practical context window.
The normal paid context window is 200,000 tokens, which is already large enough for many codebases and long conversations. Enterprise customers can access larger context sizes, and Sonnet 4.5 also supports a beta 1,000,000 token mode for very large inputs. Those options let the model keep far more of the project visible while it works. When a model can see a full spec, test logs, and the current code at once, it can make fewer mistakes from missing context.
Developers should also note the 64,000-token output capability. That allows the model to produce long documents or large code changes in a single session. Combined with checkpointing and code execution features inside Claude Code, users can iterate on larger buckets of work without constant manual stitching.
Benchmarks And How To Read Them
Benchmarks give a snapshot. They do not answer every question about real-world reliability. Still, Sonnet 4.5 performs strongly on public coding benchmarks.
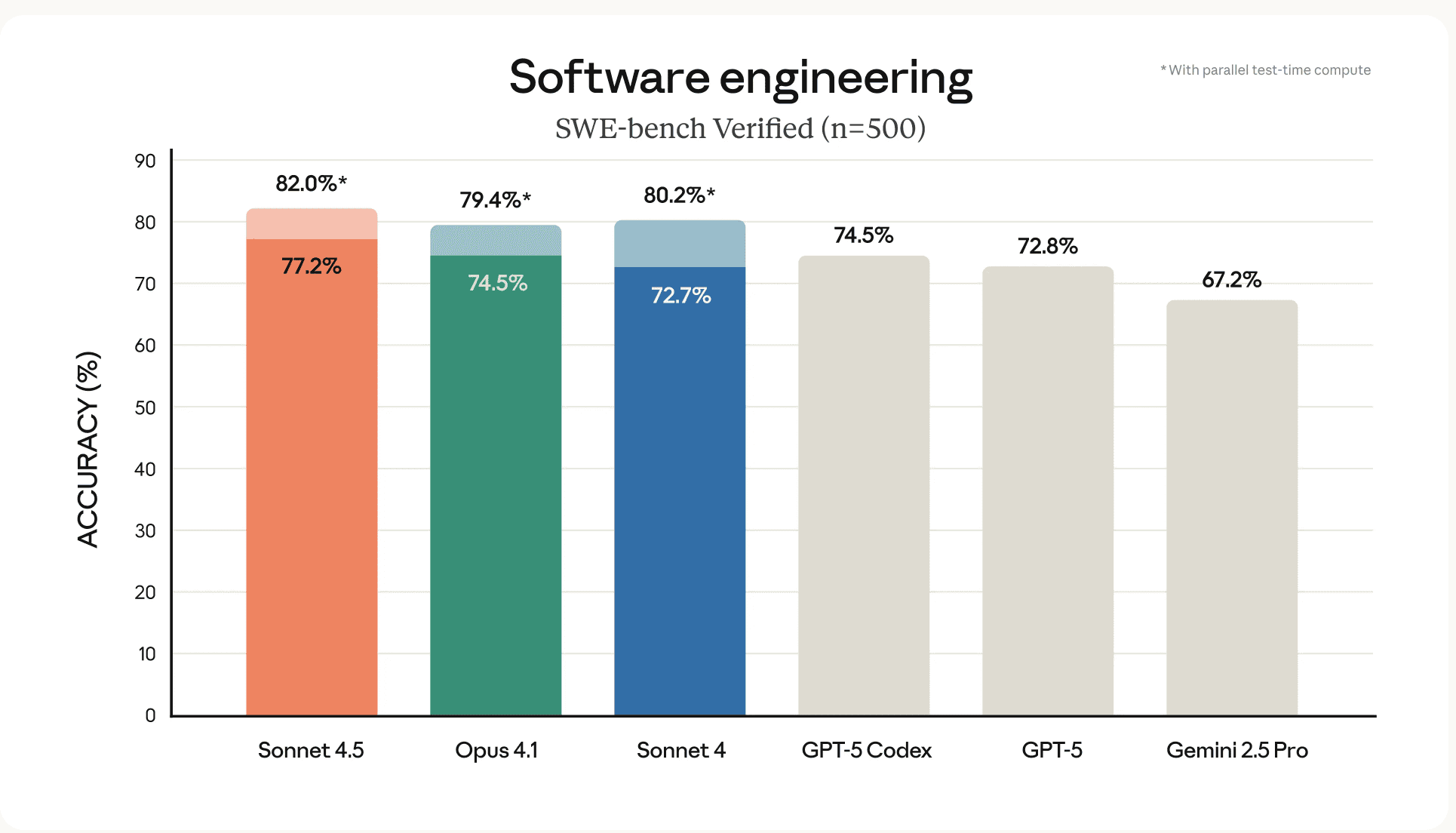
Image source: TechCrunch
The SWE-bench leaderboard places Sonnet 4.5 high among evaluated models. Anthropic also reports results with different context configurations.
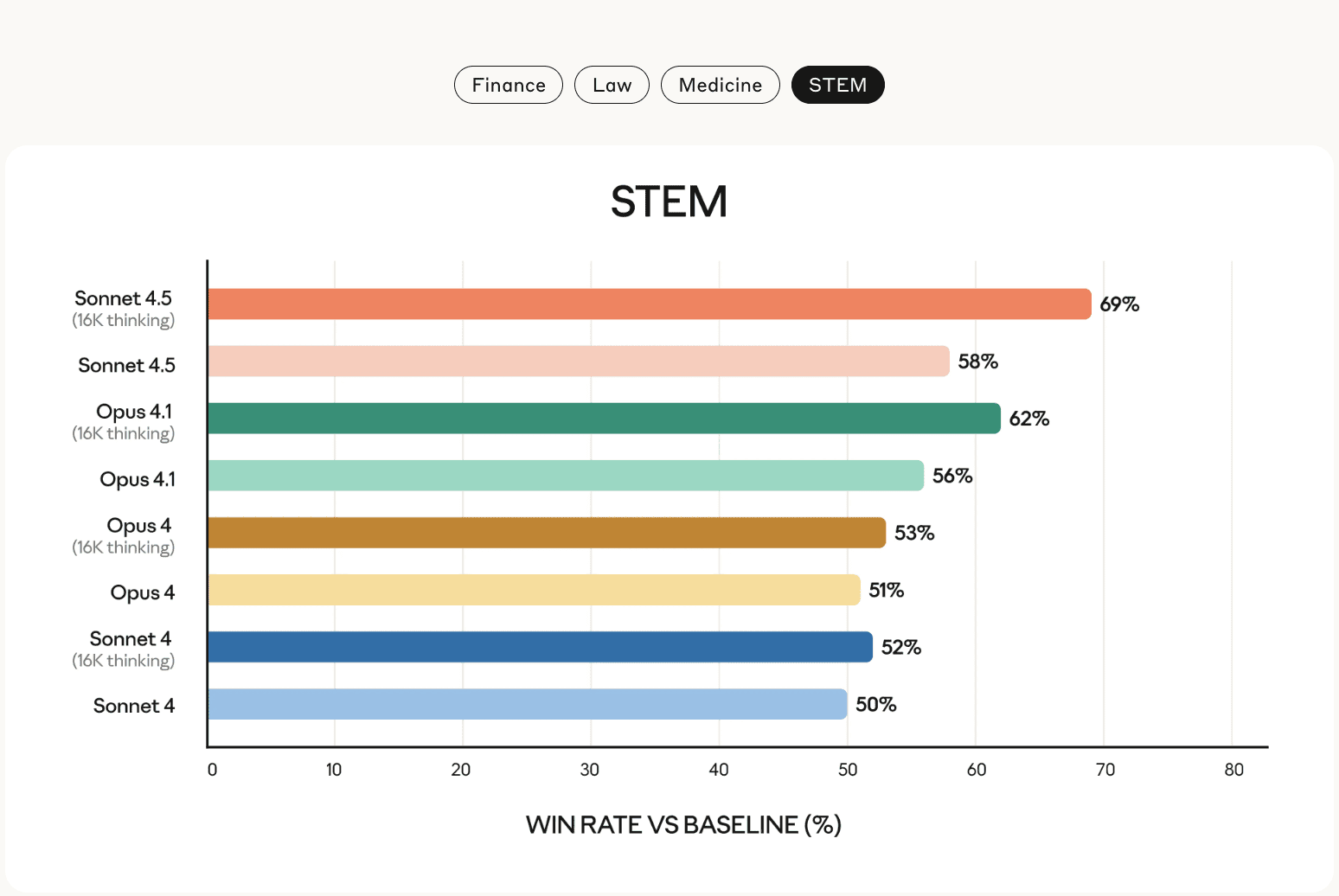
Image source: TechCrunch
The practical takeaway is that Sonnet 4.5 improves raw problem-solving on engineering tasks and that context size makes a measurable difference. Teams should use benchmark numbers to prioritize tests relevant to their own code and workflows.
Just as ChatGPT-5 showed a leap toward smarter, safer reasoning across benchmarks, Sonnet 4.5 demonstrates Anthropic’s push for reliability in extended engineering workflows.
Does Claude Sonnet 4.5 Hold Up on Safety and Alignment in Practice?
Anthropic built its company on a focus toward safer and more aligned models. Sonnet 4.5 continues that emphasis. The company describes the new model as its most aligned frontier release to date.
It tightened defenses against sycophancy, deception, and prompt injection attacks. It also reports lower false positive rates for safety filters compared to earlier models. For teams handling regulated data or operating in safety critical domains, these improvements matter.
That said, safety improvements are never perfect. Enterprises should keep human oversight in critical paths, validate model outputs with tests and audits, and have rollback plans. The longer an agent runs on its own, the more important these guardrails become.
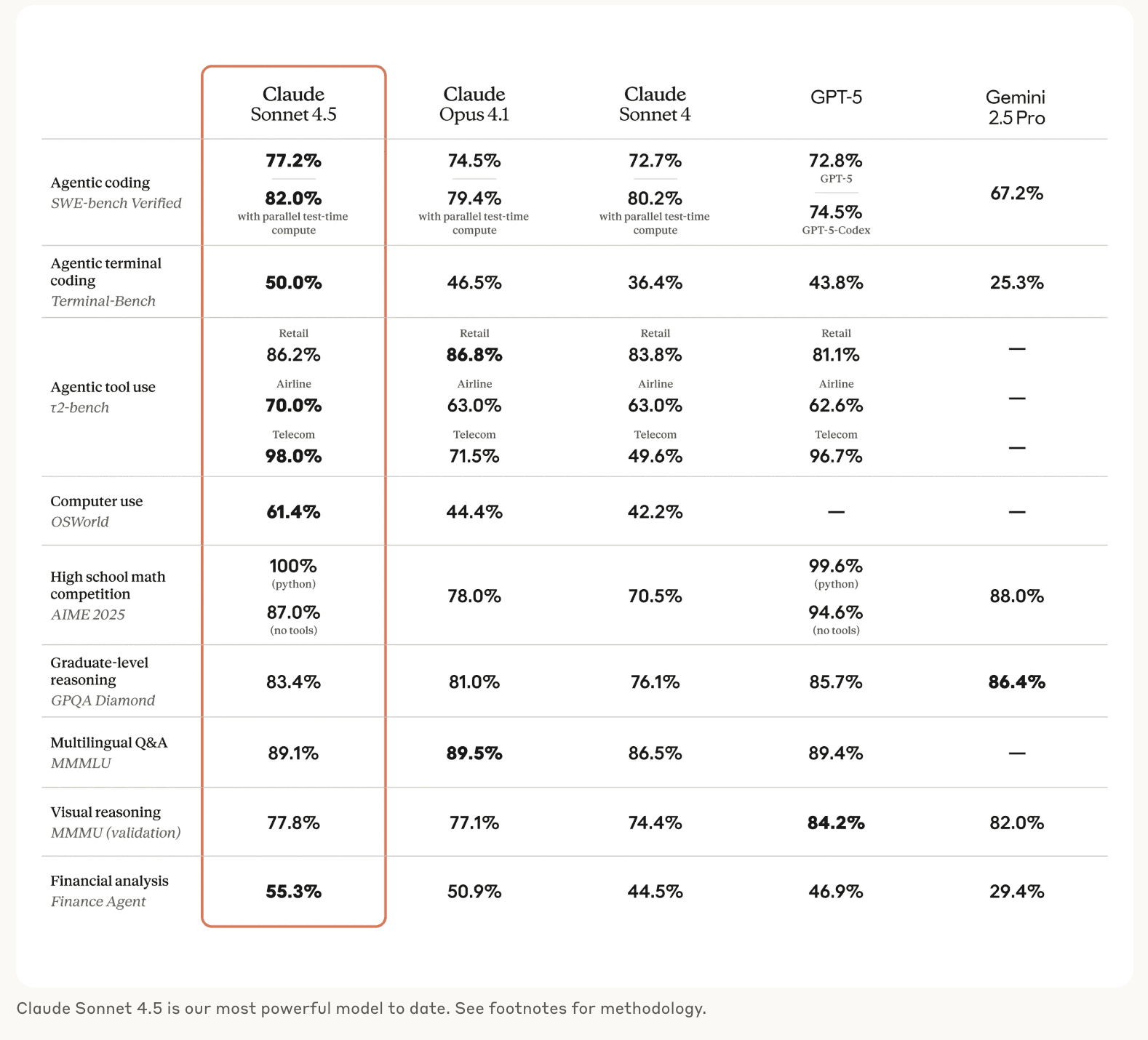
Image source: TechCrunch
This also builds on Anthropic’s earlier advances in reasoning AI, models like Claude 3.7 Sonnet showed how AI could pause, reflect, and refine its own logic, laying the groundwork for the more autonomous capabilities we see in 4.5.
How Teams Can Evaluate Sonnet 4.5 Today
Anthropic has published the model across major platforms and documented its technical capabilities. While the company doesn’t prescribe an evaluation playbook, engineering leaders can borrow from industry best practices to test Sonnet 4.5 in realistic conditions. Here are some practical steps:
- Start with a bounded pilot. Choose a small production service that needs routine maintenance, documentation, or refactoring. Run Sonnet 4.5 on the parts you are comfortable reviewing.
- Use the model inside tools you already rely on. Try it inside GitHub Copilot if you have the eligible plan, or deploy it in a sandbox in Bedrock or Vertex. These integrations are officially supported and reduce integration surprises.
- Exercise long-running sessions in monitored mode. Since Anthropic reports that Sonnet 4.5 can sustain autonomous work for 30+ hours, test this claim in your own workflows under human supervision.
- Validate end to end. Have CI and tests run automatically on any code the model produces. Require human sign-off for deployments.
- Track cost with attention to context size. Sonnet 4.5 pricing is straightforward ($3 per million input tokens, $15 per million output tokens on the standard tier), but behavior changes with larger context windows. Make sure you know the billing rules before scaling up.
These steps aren’t Anthropic’s official checklist, they are practical recommendations to help teams explore the value of Sonnet 4.5 while keeping risk low.
Where Sonnet 4.5 Fits In The Competitive Field
Anthropic is not alone in the race to make AI a dependable partner for engineers. OpenAI, Google, and others continue to push their own models. Some models show stronger scores in specific problems.
Sonnet 4.5 stakes a claim on a different axis: agentic reliability and tool use. That makes it attractive for teams that want the model to coordinate several systems and to stay on task without constant human babysitting.
Real Examples That Clarify Impact
Several companies and platform partners shared early impressions. GitHub’s Copilot integration shows how Sonnet 4.5 can be used directly inside common developer workflows, reducing the time to produce reliable code. Enterprise users also report that the model helps automate routine infrastructure tasks.
These examples are evidence, not guarantees. They show how Sonnet 4.5 can fit into real teams instead of only shining in laboratory settings.
So, Is Claude Sonnet 4.5 the Model Engineers Really Need?
The honest answer is: only partly. Sonnet 4.5 is not perfect, but it does focus on the things engineers care about most. It moves beyond one-time demos and instead aims for steady performance in real projects. The longer sessions, larger context window, and stronger coding support show that Anthropic is working on reliability in daily use.
This does not mean every task will run without errors. Teams will still need testing and oversight. But compared to earlier models, Sonnet 4.5 makes a real step toward being a tool that engineers can trust for ongoing work, not just a quick showcase.
Questions That Still Need Answers
There are open questions to watch as adoption grows. Such as:
- How does Sonnet 4.5 behave under adversarial inputs over weeks of use?
- How often will errors compound over very long sessions?
- How do teams set the right balance between autonomy and human oversight?
The model’s design reduces several common points of failure, but no system removes the need for careful engineering and human judgment.
The Practical Verdict
Claude Sonnet 4.5 is a meaningful advance in AI for software teams. It raises the bar on coding accuracy, on tool use, and on the ability to maintain long, autonomous workflows.
Anthropic has made the model broadly available across major clouds while keeping pricing consistent. The company also provided facilities for enterprise controls and larger context options. For teams that need a reliable partner for extended engineering work, Sonnet 4.5 is worth testing now.
The tech industry moves fast. New models will appear. The standard for usefulness will be real outcomes at scale. Claude Sonnet 4.5 arrives as a model that aims to help deliver those outcomes. For now, Sonnet 4.5 stands out as a model that teams can start experimenting with today while keeping an eye on how it reshapes tomorrow’s workflows.
FAQs
1. What is Claude Sonnet 4.5?
Claude Sonnet 4.5 is Anthropic’s latest AI model released in September 2025. It’s designed for coding, long autonomous workflows, and reliable tool use, making it useful for software engineering teams.
2. What makes Claude Sonnet 4.5 different from Sonnet 4.0?
Sonnet 4.5 introduces stronger coding abilities, extended autonomous task handling (up to 30+ hours in internal trials), and improved tool and file interaction. It also supports larger context windows and higher output lengths.
3. How much does Claude Sonnet 4.5 cost?
The standard pricing is $3 per million input tokens and $15 per million output tokens, the same as Sonnet 4.0. Costs may vary depending on context size and usage patterns.
4. Where can I use Claude Sonnet 4.5?
Sonnet 4.5 is available on Anthropic’s Claude platform, the developer API, Amazon Bedrock, Google Cloud, Snowflake, and in public preview inside GitHub Copilot for eligible plans.
5. How does Claude Sonnet 4.5 perform on benchmarks?
Claude Sonnet 4.5 ranks high on the SWE-bench Verified leaderboard for coding tasks, showing strong performance in problem-solving compared to other models.
6. Can Claude Sonnet 4.5 handle long tasks?
Yes. Anthropic reports that Sonnet 4.5 can sustain autonomous work for over 30 hours in internal trials, making it more reliable for extended workflows.
7. What is the context window of Claude Sonnet 4.5?
The standard paid context window is 200,000 tokens. Enterprise customers can access larger sizes, and a beta option supports up to 1 million tokens for very large projects.
8. Is Claude Sonnet 4.5 safe to use?
Anthropic emphasizes safety and alignment in Sonnet 4.5. It has improved defenses against sycophancy, deception, and prompt injection. Still, human oversight and validation remain essential in production use.
9. How can teams evaluate Claude Sonnet 4.5?
Teams can start with small pilots, test the model in GitHub Copilot or cloud sandboxes, run supervised long sessions, and validate outputs with CI/CD and testing before moving to production.
10. How does Claude Sonnet 4.5 compare to other AI models?
While OpenAI, Google, and others lead in certain benchmarks, Claude Sonnet 4.5 focuses on reliability, tool use, and long-context workflows, making it especially attractive for engineering teams that want stable, end-to-end task execution.
Just published



