Trusted by Market Leaders in Education, Travel, Finance and E-commerce since 2007





We put excellence, value and quality above all - and it shows






A Technology Partnership That Goes Beyond Code

“Arbisoft has been my most trusted technology partner for now over 15 years. Arbisoft has very unique methods of recruiting and training, and the results demonstrate that. They have great teams, great positive attitudes and great communication.”










How RAG Pipelines Power Analytics with LLMs and Data Engineering


In the last few years, Large Language Models (LLMs) have changed the way businesses think about data analytics. Traditionally, data engineering was about building robust pipelines to collect, clean, and transform data for reporting and decision making. But with LLMs, new paradigms have emerged, especially Retrieval-Augmented Generation (RAG), which allows analytics pipelines to use both structured and unstructured data in real-time. Let’s see how LLMs and data engineering intersect and why RAG is a game-changer for analytics.
Introduction to LLMs and Data Engineering
Data engineering has always been the backbone of analytics. Engineers build ETL/ELT pipelines that take raw data and process it into a structured format for analysis. Historically, this meant:
- Extracting data from databases, APIs, or streaming platforms.
- Transforming it with tools like Apache Spark or dbt.
- Loading it into data warehouses like Snowflake, BigQuery, or Redshift.
Meanwhile, LLMs like GPT, LLaMA, and others have changed how we interact with data. Instead of writing complex SQL queries or dashboards, analysts can now ask natural language questions and get answers synthesized from multiple sources.
But LLMs have limitations. They are knowledge-static (limited by their training data) and often hallucinate facts. This is where Retrieval-Augmented Generation comes in.
What is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation is a technique that combines generative AI with retrieval-based systems. Unlike standard LLM outputs, RAG pipelines can query external knowledge sources in real-time before generating a response.
Core Idea:
- Retrieve: Query a vector database, document store, or data warehouse to fetch relevant documents or data snippets.
- Generate: Feed these retrieved results into an LLM that synthesizes and generates accurate answers.
RAG ensures the outputs are grounded in real data, reducing hallucinations and improving accuracy in analytics queries.
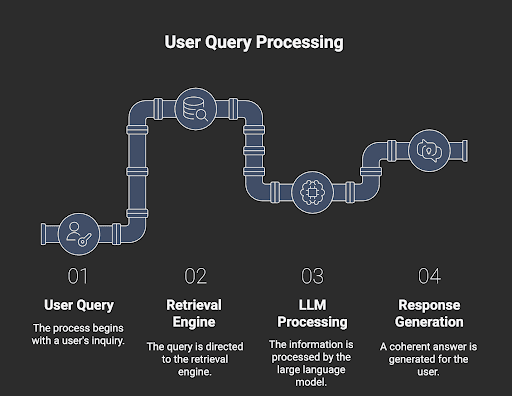
Why RAG Matters for Analytics
Analytics teams face growing challenges:
- Data volume explosion: Enterprises produce petabytes of structured and unstructured data.
- Complexity of queries: Users want insights that span multiple datasets and document sources.
- Real-time decisions: Business decisions often require up-to-date information.
By combining LLMs with RAG, companies can:
- Answer natural language queries on business data.
- Perform cross-domain analytics, integrating structured and unstructured data.
- Reduce dependency on traditional BI dashboards for exploratory analytics.
Example use cases:
- Financial Analytics: LLMs can generate reports by retrieving data from accounting systems, transaction logs, and market research.
- Customer Support: Automatically summarize support tickets by fetching historical interactions.
- Healthcare: Combine patient records with medical literature for insights into treatments.
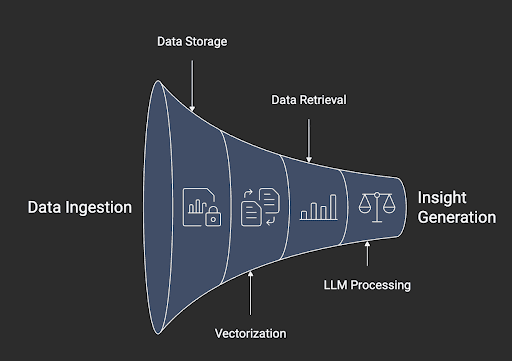
Components of a RAG-Powered Data Pipeline
Building a RAG pipeline requires combining traditional data engineering with modern AI components:
a. Data Ingestion Layer
- Collect structured data from databases, data lakes, APIs.
- Collect unstructured data: PDFs, logs, emails, documents.
- Tools: Apache Kafka, AWS Glue, Apache NiFi.
b. Data Storage and Processing
- Store structured data in data warehouses (Snowflake, BigQuery).
- Store unstructured data in document stores or vector databases.
- Use data transformation tools (dbt, Spark) to clean and standardize data.
c. Embeddings and Vectorization
- Convert textual or semi-structured data into vector embeddings.
- LLMs or models like OpenAI embeddings or Sentence-BERT can be used.
- Store embeddings in vector databases for fast retrieval.
d. Retrieval Layer
- Implement a semantic search engine using embeddings.
- Tools: FAISS, Pinecone, Weaviate.
- Retrieve contextually relevant data for the LLM to consume.
e. LLM Layer
- Feed the retrieved documents along with the user query into the LLM.
- Fine-tune LLM prompts to generate analytics-friendly responses.
- Optionally, implement response validation to reduce hallucinations.
For a practical demonstration of these concepts, I built a RAG pipeline using FAISS for retrieval and Google Gemini 2.0 for generation. The implementation ingests financial news tweets, vectorizes them, retrieves relevant documents based on queries, and generates analytics-friendly summaries. The demo is available on GitHub.
Step-by-Step Guide to Building RAG Pipelines
1: Identify the Data Sources
- Structured: SQL, NoSQL, CSV, Parquet.
- Unstructured: PDFs, emails, logs.
2: Preprocess Data
- Clean structured data: Handle missing values, normalize columns.
- For unstructured data: Extract text using OCR or PDF parsers.
3: Generate Embeddings
- Choose an embedding model based on your language/domain.
- Convert textual data into dense vectors for semantic search.
4: Build Retrieval Engine
- Use a vector database for fast similarity search.
- Index embeddings and metadata for easy filtering.
5: Query and Generate
- User query → Retrieval engine fetches top-k relevant documents.
- Feed documents into LLM with a carefully designed prompt: “Based on the following data, summarize key insights related to revenue trends in Q3 2025.”
6: Validate and Output
- Post-process the generated results.
- Optional: Apply business rules to ensure numeric consistency.
Best Practices
- Prompt engineering: Tailor prompts to make outputs actionable.
- Hybrid retrieval: Combine keyword search with vector search for maximum coverage.
- Version control: Track dataset versions to ensure reproducibility.
- Monitoring: Track LLM output quality and retrieval relevance.
Challenges
- Data freshness: Embeddings can become outdated; re-index periodically.
- Scaling: Large datasets require optimized vector search and distributed storage.
- Cost: LLM inference can be expensive; optimize queries and use caching.
Future of LLM + Data Engineering in Analytics
LLMs are just starting to be integrated with data engineering pipelines. We can expect:
- Real-time analytics: Continuous streaming data feeding directly into RAG pipelines.
- Autonomous data engineers: AI tools that suggest transformations, detect anomalies, and build dashboards.
- Domain-specific RAG models: LLMs tuned to financial, healthcare, or industrial data.
RAG is a fundamental shift: analytics pipelines are no longer just about storing and processing data. They are about interacting with it intelligently so humans can get insights faster and more accurately.
Conclusion
RAG is changing analytics by combining data engineering discipline with LLM smarts. For companies, this means faster insights, better decisions, and the ability to use unstructured data that was previously impossible to analyze. By building RAG pipelines, analytics teams can deliver contextually accurate, data-driven insights—the future of business intelligence.
Just published



