Trusted by Market Leaders in Education, Travel, Finance and E-commerce since 2007





We put excellence, value and quality above all - and it shows






A Technology Partnership That Goes Beyond Code

“Arbisoft has been my most trusted technology partner for now over 15 years. Arbisoft has very unique methods of recruiting and training, and the results demonstrate that. They have great teams, great positive attitudes and great communication.”











From Workflows to Workflows-That-Work: How AI Is Rewriting Enterprise Process Design


Data pipeline failure shows up long before an incident report is written. Dashboards go stale. Reports arrive late. Analytics teams stop trusting their inputs. For CIOs and CTOs, these failures accumulate into strategic risk, not isolated technical defects.
As data platforms expand across external APIs, third-party vendors, streaming systems, semi-structured sources, and legacy infrastructure, leaders are accountable for ensuring data pipelines remain reliable, scalable, governed, and adaptable to change. When pipelines break due to schema drift, brittle transformations, or missing observability, the impact is strategic, not operational.
This blog addresses that accountability. It explains how modern data and technical workflows, enhanced by AI workflow automation, machine learning, metadata management, observability, and automated data quality checks, are reshaping enterprise process design. The focus is not on tools or tactics, but on how organizations move from fragile, reactive pipelines to scalable, adaptive, and reliable intelligent workflows that leadership can trust.
Why Traditional Data Pipelines Break And Why That Matters
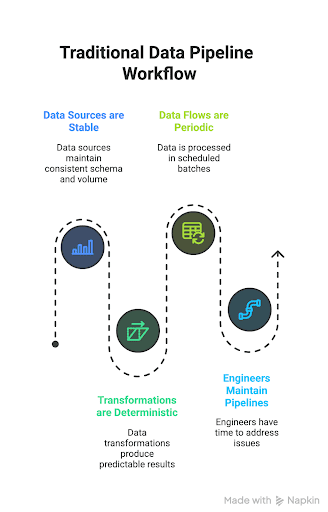
Most legacy data workflows in enterprises share common assumptions:
- Data sources are stable: schema, data types, volume.
- Transformations are deterministic and fixed.
- Data flows are periodic or batch-based (overnight ETL, nightly loads).
- Engineers have time to maintain, fix, and monitor whenever failures arise.
That model worked when systems were simpler, data sources were fewer, and data volumes were lower.
Today, nothing is truly stable. Data flows in from external APIs, streaming logs, IoT devices, third-party vendors, JSON or schemaless sources, and legacy systems in the process of migration. Volumes fluctuate, formats evolve, and business rules constantly shift. In this environment, fixed pipelines often struggle because:
- A schema change upstream (a renamed column, new field, or changed data type) will break transformations or downstream loads.
- Error handling becomes brittle; pipelines may silently drop bad records or corrupt data.
- Manual maintenance becomes unsustainable: engineers are always chasing breakages, not building value.
- Lack of observability and metadata means root causes are hard to trace, leading to repeated issues and declining trust in data.
- Scaling becomes costly. Adding new sources or increasing throughput often requires rewriting or retesting large portions of the pipeline.
These failures are not just technical hiccups. They impact business decisions, slow down analytics, undermine confidence, and can turn data from a valuable asset into a liability.
Leaders who run large data platforms describe the same pattern. Barr Moses, co-founder and CEO of Monte Carlo, a US-based data observability company, uses the term "data downtime" for these moments when data is missing, stale, or broken, and teams only discover the problem when a dashboard or model has already been affected. In her writing and talks, she argues that without a dedicated observability layer around pipelines, these failures remain invisible until they hurt decisions.
A 2023 study of data pipelines identified 41 factors that influence pipeline quality. It found that data-related issues are mainly caused by incorrect data types and occur most often in the cleaning and ingestion stages, with integration and related processing steps also prominent problem areas, precisely the phases that are brittle under change.
In short, traditional workflows are fragile. For enterprises depending on fast, accurate, scalable data, this fragility is a strategic risk.
But not every practitioner believes that smarter, AI-enabled workflows on their own solve this fragility. Ben Rogojan, a US-based data engineer and founder of Seattle Data Guy, often points out that AI will not rescue teams from poor modeling, weak governance, or under-invested infrastructure. In his work with companies that want “AI on the roadmap,” he returns to the same theme. The basics of sound data engineering still decide whether pipelines are reliable. AI-driven validation and clever automation are step two, not step one.
What Next-Gen Data Workflows Offer
Modern data workflows do not depend on assumptions of stability. They are built to adapt, self-validate, and survive change. These workflows combine AI and ML techniques, metadata and lineage systems, observability, and automated quality gates.
Here is what a robust, modern data workflow architecture looks like and why each component matters for you as a decision maker.
1. Schema Inference And Schema Evolution Handling
Many modern data pipelines begin with data sources that may not have strict schemas (JSON logs, third-party APIs, semi-structured sources). Relying on manual schema mapping leads to brittleness whenever upstream changes.
Instead, AI- and ML-powered schema inference can analyze incoming data to detect structure, types, nested fields, optional fields, and suggest appropriate target schema definitions. Some systems even support automated schema evolution: when the source schema changes, the pipeline can flag or adapt the target schema and transformation logic accordingly.
For a CIO or Head of Data Platforms, that means reduced maintenance burden.. Onboarding a new data source may not require full-time engineering work. The pipeline adjusts itself. Manual rewrites drop sharply.
This direction is consistent with how Chad Sanderson, co-founder and CEO of Gable.ai (a US-based data platform focused on data contracts and shift-left data quality), talks about pipeline reliability. His work on data contracts argues that teams must make structure and expectations explicit at the boundary between producers and consumers. Schema inference and evolution give you visibility into what the data really looks like; contracts ensure that changes are surfaced and owned, not quietly pushed downstream to break reports and models.
2. Automated Data Quality And Anomaly Detection
Once data is ingested, the risk of dirty, inconsistent, or malformed data increases with volume. Manual validation fails at scale. Errors slip through, bad data corrupts analytics, and ML models get poisoned.
Modern pipelines embed automated data quality scoring frameworks. For example, the DQSOps framework uses machine learning to predict and score data quality across several dimensions, such as accuracy, completeness, consistency, timeliness, and skewness, and can be integrated into DataOps workflows as an automated scoring layer.
Another system, described in the paper Auto Validate by History, uses historical runs of the pipeline to automatically generate data quality rules and constraints. When a recurring pipeline runs, the system compares new data against historical norms and flags deviations (schema drift, missing values, anomalies).
When embedded in production pipelines, this automated validation dramatically reduces human effort, catches errors early, and builds trust in downstream applications (dashboards, analytics, ML models). For executive leadership, bad data at the foundation translates directly into wrong decisions at the top.
This is also how Tristan Handy, founder and CEO of dbt Labs in the United States, frames the problem from an analytics engineering perspective. dbt Labs popularized the idea that transformations and assumptions about data should live in version control, with explicit tests that run on every pipeline execution. Data quality becomes something you assert and verify continuously, not a one-time clean-up project.
3. Metadata, Lineage, Observability, And Auditability
In complex enterprises, many pipelines run across systems: ingestion, staging, transformation, warehousing, BI, ML training, serving. Without proper metadata and lineage, tracking where data came from, which transformations were applied, and when problems emerged becomes almost impossible.
Modern workflows embed metadata management systems that tag each dataset version, log transformation history, record schema versions, and track lineage across systems. This supports auditing, compliance, traceability, and debugging.
Quality-aware data engineering frameworks encourage embedding these systems by default. They also highlight the need for version control, change logs, and systematic lifecycle management.
For decision makers, this builds enterprise-grade governance into data systems. Risk is reduced, regulatory compliance becomes easier, and audits become feasible without chaos.
This is also where Moses’s data observability message connects directly. A dedicated layer that monitors freshness, volume, schema changes, and lineage gives leaders a live view of how healthy the pipelines are, instead of relying on user complaints as the first signal that something went wrong.
4. Adaptive Orchestration, Resource Management, And Self-Healing Pipelines
Instead of fixed batch schedules, modern data workflows incorporate orchestration platforms that enable enterprise automation, turning pipelines into intelligent processes that scale dynamically and self-correct when data or workloads change. When ingestion volume spikes, the pipeline can compute resources dynamically, adjust parallelism, or queue jobs intelligently.
Furthermore, pipelines can embed retry logic, fallback paths, and automated recovery when failures occur. With AI-driven anomaly detection, the system can often identify root causes and trigger corrective flows, for example, rejecting bad records, alerting engineers, or rerunning with adjusted logic.
These design patterns are especially critical for high-throughput, real-time, or near real-time data systems (IoT, logs, streaming data). Papers exploring "smart pipeline" design highlight these orchestration and robustness features as core to next-gen data engineering.
For a CTO or VP of Engineering, that means improved reliability, fewer outages, and less firefighting. Your data infrastructure becomes more like a resilient service platform than a fragile collection of scripts.
5. Integration Of Data Workflows With ML, Analytics, And Downstream Systems, With Consistency Guarantees
When pipelines feed ML models, analytics, dashboards, and decision systems, the cost of data inconsistencies or drift is high. Modern workflows ensure that data transformations used during model training are applied identically in production pipelines. They enforce feature engineering consistency, data versioning, and data contract enforcement across training and serving environments.
That makes the difference between models that perform well in testing and models that degrade silently in production. For a CTO or CIO, that ensures AI and ML investments deliver real value, not hidden technical debt.
This is exactly where Sanderson’s data contract view and Handy’s analytics engineering practices meet. Contracts define what downstream systems should expect. Versioned, tested transformations in tools like dbt enforce those expectations across both training and serving, instead of letting every pipeline reinvent its own logic.
6. Continuous Monitoring, Feedback, And Maintenance
Traditional pipelines often lack systematic monitoring until something breaks. Modern workflows treat monitoring and maintenance as essential parts of pipeline design. That includes continuous data quality monitoring, automatic alerts on anomalies, retraining triggers for ML validation, versioning, and rollback mechanisms.
Recent studies on data pipeline failures found that many problems emerge in cleaning, ingestion, and integration phases, often due to incorrect data types or incompatible transformations. By embedding monitoring at these stages, you drastically reduce risk and increase stability.
The practitioners mentioned earlier are all pushing in the same direction on this point. Moses talks about eliminating data downtime, not just reacting to it. Sanderson focuses on shifting data quality concerns closer to the source, so defects are caught before they multiply. Handy’s analytics engineering community treats testing and documentation as non-negotiable parts of every production dataset. Together, their work reinforces the idea that pipelines are living systems that need ongoing care, not one-off scripts that can be forgotten once they "work."
For organizational leaders, this transforms pipelines from "build and forget" scripts into living infrastructure. They require steady care, but offer predictable reliability.
What Research And Experts Show: Benefits And Risks
This architecture is not a fantasy. In 2023, a paper titled "AI Driven Data Engineering: Streamlining Data Pipelines for Seamless Automation" documented a working framework embedding ML, NLP, metadata management, adaptive ingestion, and transformation logic that responds to schema changes and recommends pipeline configurations with minimal human oversight.
Independent research on data pipeline quality identified that a large fraction of pipeline failures (around one third) come from incorrect data types or data cleaning issues, and ingestion and integration phases are among the most problematic for developers.
A 2025 study in an industrial environment showed how building a modular data quality pipeline for production data, with components for ingestion, profiling, validation, and continuous monitoring across dimensions like accuracy, completeness, consistency, and timeliness, improved reliability and monitoring.
At the same time, other research raises caution. A study on the effects of data quality on ML performance shows that poor or inconsistent training data leads to degraded models and unreliable decisions.
These findings lead to a clear conclusion. Smart pipelines offer real advantages, but they succeed only when data quality, metadata, governance, and lifecycle management are taken seriously. Automation can amplify good practices. It can also amplify bad data.
The experiences of US-based practitioners like Barr Moses (data observability and data downtime), Chad Sanderson (data contracts and shift-left data quality), and Tristan Handy (analytics engineering and tested transformations) line up closely with that conclusion. Each, from a different angle, is arguing for the same thing this architecture requires: clear ownership, continuous validation, and visibility across the entire pipeline.
Some experts also warn about a different kind of risk. Stepan Pushkarev, a US-based co-founder and AI leader at Provectus, argues that AI is not a silver bullet. It is just an instrument, like the cloud or the web, and it quickly becomes an expensive distraction if it is not tied to a clear mission and measurable outcomes. From that point of view, even the most advanced AI-driven data workflows make sense only when they are anchored to specific use cases and defined ROI, not built as infrastructure for its own sake.
What This Means For You: Decision Maker Guidelines
If you lead technology, data, or operations, here is how to translate these insights into action.
Where AI-Enabled Data Workflows Make The Most Sense
AI-enabled and modern data workflows are especially valuable when:
- Your enterprise ingests data from many sources (databases, third-party systems, streaming logs, APIs) with variable schema or semi-structured formats.
- You deal with large volumes, velocity, or variety of data, such as high throughput, bursty loads, real-time streams, or scaling needs.
- Your analytics, reporting, or ML and AI initiatives depend on high data reliability, consistency, and governance.
- Existing pipeline maintenance consumes significant engineering hours, with inconsistent performance or recurring breakages.
- Compliance, audit, traceability, data lineage, and metadata are important (regulated industries, multi-tenant data, collaborations, and governance requirements).
In these cases, investing in next-gen data workflows is not a "nice to have." It is foundational infrastructure.
What You Must Do Before Blindly Adopting Automation
- Evaluate your existing data quality. If upstream sources are inconsistent or poorly managed, automation will amplify issues instead of fixing them.
- Build metadata and lineage tracking from day one. Without it, pipeline complexity will explode and debugging or audits will become impossible.
- Embed data validation, anomaly detection, and schema change detection as mandatory gates before any downstream load or ML training.
- Treat pipelines as living infrastructure. Invest in monitoring, logging, versioning, maintenance, retraining, and periodic audits.
- Ensure governance, security, and compliance, especially if you handle sensitive data or work in regulated domains.
- Expect that adoption is incremental. Start with pilot workflows, not a big bang across all pipelines.
This is the same playbook you see in practice at organizations that follow the paths laid out by Moses, Sanderson, and Handy. They do not try to "automate everything" overnight. They pick critical pipelines, wrap them in observability, contracts, and tests, learn from the results, and expand.
Implementation Roadmap: Phased, Controlled & Strategic
Here is a practical roadmap for enterprises ready to move from brittle pipelines to adaptive workflows.
1. Inventory and baseline
Map all data sources, pipelines, and transformations. Document failure history, maintenance burden, data volume and velocity, types of ingestion (batch vs streaming), schema variability, and downstream dependencies.
Expected outcome: Clear visibility into failure hotspots, baseline downtime, and engineering hours spent on maintenance.
2. Select pilot workflows with high pain and high value
Identify 1 to 3 pipelines that are critical (analytics, ML, business reporting) but manageable in scope and representative of bigger challenges such as variable schema sources, high volume, or frequent changes.
Expected outcome: 20–30% reduction in incidents or manual intervention within pilot pipelines.
3. Implement metadata and lineage layer
Use or build systems to track dataset versions, transformations, schema versions, provenance, timestamps, and audit logs. This foundation supports governance, traceability, and debugging.
Expected outcome: Faster root-cause analysis and improved audit readiness.
4. Add data quality and validation automation
Embed tools and frameworks (for example, DQSOps, Auto Validate by History-style systems) to monitor completeness, consistency, anomalies, and schema drift. Run quality checks as part of pipeline execution, not as an afterthought.
Expected outcome: Fewer downstream failures and earlier detection of data anomalies.
5. Integrate schema inference and adaptive transformation logic
For semi-structured or variable schema sources, use schema inference or adaptive mapping tools to reduce manual mapping and minimize breakages when upstream changes occur. Combine this with explicit data contracts where possible so teams know which changes are safe and which require coordination.
Expected outcome: Reduced pipeline breakage caused by upstream schema changes.
6. Introduce orchestration and resilience mechanisms
Use modern orchestration platforms supporting dynamic resource allocation, retry logic, fallback paths, anomaly-triggered alerts or corrections, and parallelization when needed. Handle both batch and streaming workloads. Aim for the kind of resilience that makes data downtime rare and brief, not a recurring surprise.
Expected outcome: Improved uptime and shorter recovery times during failures.
7. Run test cycles, monitor, and refine
Track metrics such as error rate, data quality scores, pipeline uptime, latency, resource utilization, and downstream data failures. Compare with your baseline. Improve thresholds, validation logic, and error handling based on what you learn.
Expected outcome: Declining error rates and clearer performance trends.
8. Scale gradually and institutionalize
Once pilots stabilize, gradually extend to more pipelines. Build a centralized DataOps or Data Engineering team or Center of Excellence. Define governance, documentation, SLAs, data contracts, and maintenance processes.
Expected outcome: Predictable scaling without proportional headcount growth.
9. Embed compliance, security, and versioning
Add role-based access, encryption, data masking for sensitive data, audit trails for transformations, and compliance checks (especially for regulated data and PII).
Expected outcome: Lower compliance risk and faster audits.
10. Treat pipelines as long-lived products, not one-time tasks
Accept that data workflows evolve with business, data sources, regulations, and performance needs. Maintain, refine, and invest in them over time, the way you would with any other critical product.
Expected outcome: Long-term platform stability with reduced technical debt.
Let’s Conclude
Read together, the perspectives of Barr Moses, Chad Sanderson, and Tristan Handy, and the more cautious views of Ben Rogojan and Stepan Pushkarev, do not cancel each other out. They describe the same answer from different angles: use modern, automated data workflows, but only on top of strong data engineering fundamentals and a clear, ROI-linked mission.
If your enterprise depends on data pipelines for analytics, reporting, AI, ML, or operations, then static, brittle workflows are a hidden risk. They bottle up growth, reduce agility, erode data trust, and cost you in maintenance and delays.
Modern data workflows that combine schema inference, AI workflow automation, data quality automation, metadata and lineage, adaptive orchestration, validation, and monitoring represent a new paradigm of enterprise automation and intelligent processes. Think of it like the ERP + Data Lake + AI triangle: solid, unified foundations make AI-driven workflows truly effective.
The perspectives of Barr Moses (US-based co-founder and CEO of Monte Carlo), Chad Sanderson (US-based co-founder and CEO of Gable.ai), and Tristan Handy (US-based founder and CEO of dbt Labs) reinforce that this shift is already underway. Each is working with teams that have lived through pipeline fragility and are now investing in observability, contracts, and analytics engineering to make workflows that actually work.
For decision makers such as COOs, CIOs, CTOs, and process leaders, this is a strategic choice. It is not trendy. It is infrastructure engineering. It is about building resilience, agility, and reliability into the systems that feed every report, dashboard, and model you rely on.
If you are ready to move forward, treat data pipelines as first-class infrastructure. Invest in metadata, observability, quality, and automation. Start with pilots. Build incrementally. Scale thoughtfully. Because when data workflows truly work, your entire data ecosystem works. Your teams work. Your decisions work. Your growth works.
Just published



