Trusted by Market Leaders in Education, Travel, Finance and E-commerce since 2007





We put excellence, value and quality above all - and it shows






A Technology Partnership That Goes Beyond Code

“Arbisoft has been my most trusted technology partner for now over 15 years. Arbisoft has very unique methods of recruiting and training, and the results demonstrate that. They have great teams, great positive attitudes and great communication.”











Opus 4.8 Looked Worth It, Until Sonnet 5 Changed the Math


TLDR
Sonnet 5 shipped June 30, 2026, and it makes Opus 4.8's premium optional for a lot of production work.
- Opus 4.8 earns its price only when a failed run costs more than the model.
- Its 88.6% SWE-bench Verified score justifies a trial, not a production default.
- A leaderboard win does not prove business value on your actual codebase.
- Opus 4.8 costs $5/$25 per million input/output tokens. Sonnet 5 costs $2/$10 introductory.
- Anthropic says Sonnet 5 matches Opus 4.8 on some tasks at higher effort levels.
- Cost per accepted outcome, not token price, decides the model.
- Route by workload class instead of picking one universal winner.
Run one 30-day task-weighted evaluation before committing either model to production.
Introduction
The premium case for Opus 4.8 was easy to state when it arrived in May 2026: pay more when a failed run costs more than the model. That still holds. What changed on June 30, 2026 is that Sonnet 5 made the premium optional for a wider share of production work.
For a large language model (LLM) team, this is not a contest over prestige. It is a production language-model selection problem: which model clears the required quality threshold at an acceptable cost, latency, and operational risk for each workload class?
The Original Case for Paying More for Opus 4.8
A premium model earns its place by preventing expensive failures, not by carrying a premium label. That argument is strongest where a weak answer consumes substantial developer time, triggers a costly retry, or creates a risk that a reviewer cannot cheaply detect.
Anthropic positions Opus 4.8 for complex coding, reasoning, and research-heavy work. Its launch material reported an 88.6% result on SWE-bench Verified, while early-access accounts described stronger end-to-end completion on agentic tasks. Those signals justify a trial, not an automatic production default.
The Work That Can Justify a Premium Model
Long-horizon agentic work is the clearest fit. A multi-file code change or a tool-using workflow can burn through a large context, many calls, and a meaningful amount of engineering attention before a failure becomes visible. A run that breaks late costs more than its final token bill because the team must diagnose it, retry it, and unblock dependent work.
The same logic applies when human review is costly. A contract-analysis workflow, financial-document interpretation flow, or internal code agent may still require review either way. The premium becomes defensible when Opus 4.8 reduces substantive corrections enough to outweigh its higher model spend.
Why a Benchmark Win Does Not Automatically Create Business Value
A public benchmark is a screening signal, not an acceptance criterion. SWE-bench Verified evaluates whether an agent produces patches that pass existing tests for real GitHub issues. It does not model your codebase conventions, missing tests, tool definitions, or reviewers' unwritten standards.
The European Commission's AI benchmarking work identifies recurring limitations in benchmark validity and transferability. The practical implication is simple: a model can lead on a controlled task while creating more remediation in production. Measure the entire system, including prompts, tools, retries, and reviewer effort, before treating a leaderboard result as business value.
Sonnet 5 Changes the Comparison Only Where It Changes the Work
Sonnet 5 changes the decision only when it reaches the same acceptance threshold on the work you actually run. Anthropic says that, at higher effort levels, Sonnet 5 can match Opus 4.8 on selected tasks. That is a conditional claim, and it is the right one.
“Close” is not a useful operating metric. Accepted-output rate, failure type, response time, and recovery cost are.
How Close Is Close Enough on Your Actual Task Mix?
Start with task-weighted evaluation rather than an overall benchmark. Pull 50 to 100 recent tasks from production logs, group them by workload class and difficulty, then assign each task the weight it carries in real volume or business risk. Easy prompts can dominate a random sample while revealing almost nothing about the decisions that drive correction cost.
For each output, record whether it passes the real gate. In a coding flow, that might mean tests pass and code review needs no substantive change. In a document workflow, it could mean the output needs only light editing. For a tool-using agent, record whether it selected the correct tool, supplied valid arguments, recovered from an error, and completed the requested work.
Vendor benchmark charts can establish a reason to test. They cannot establish that an 88.6% vendor-reported score for Opus 4.8, or an effort-dependent Sonnet 5 result, maps to your acceptance rate. The hardest 10 to 20 percent of tasks deserve disproportionate attention because that is where a narrower capability gap can become an expensive operational gap.
Where Speed and Unit Economics Alter the Production Decision
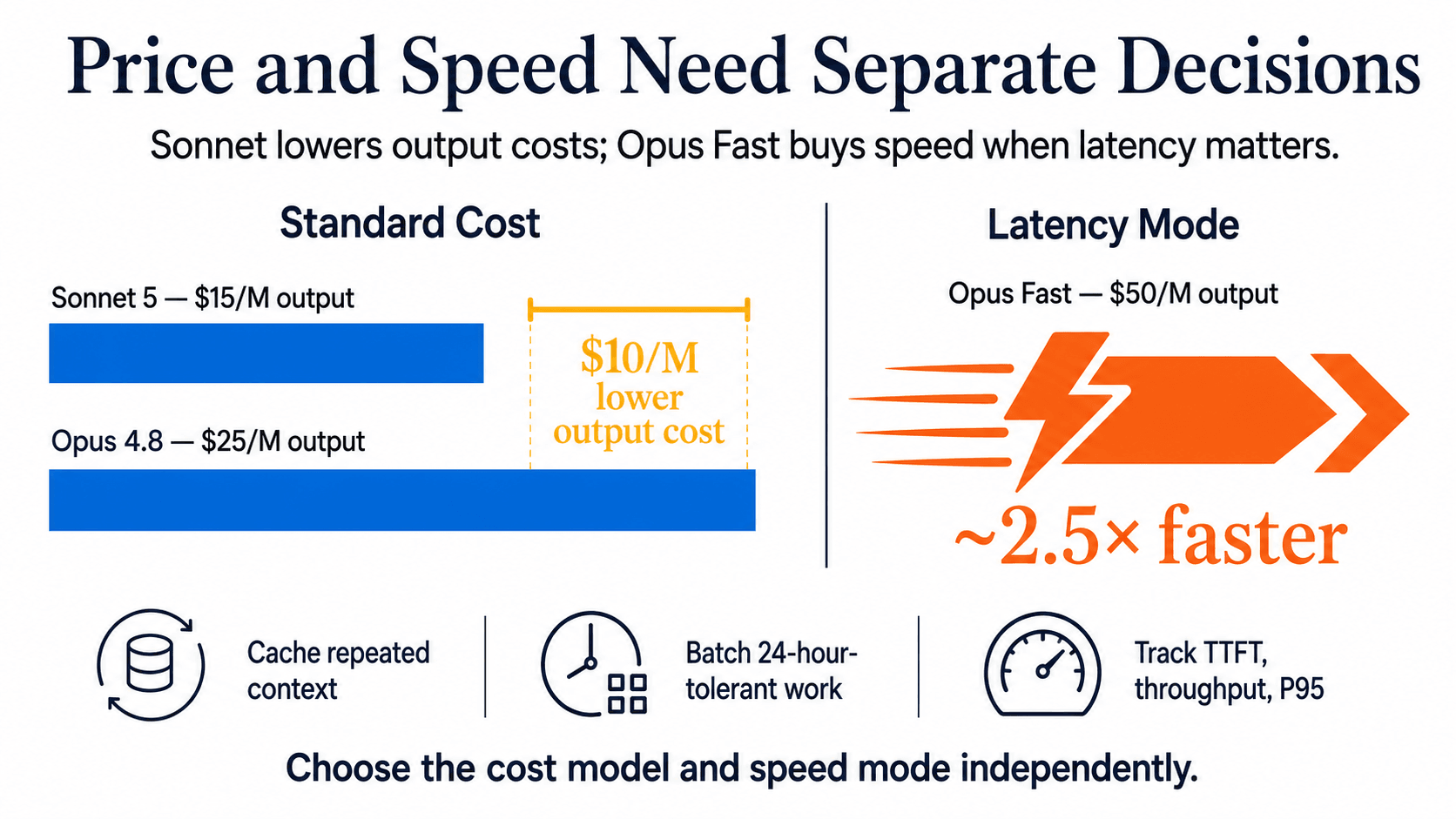
The June 30, 2026 pricing snapshot makes the arithmetic material. Opus 4.8 standard pricing was listed at $5 per million input tokens and $25 per million output tokens. Sonnet 5 was listed at $2 and $10 during its introductory period, then $3 and $15 after September 1, 2026. At standard Sonnet 5 pricing, each million output tokens represents a $10 difference before caching, batch processing, retries, or review.
Fast Mode changes the latency calculation, not the list-price advantage. Opus 4.8 Fast Mode was priced at $10 per million input tokens and $50 per million output tokens, with approximately 2.5 times faster output. That may be a rational trade in latency-sensitive work, but it should be evaluated as a separate operating mode.
Compare the native application programming interface (API) conditions you will actually use. Prompt caching can reduce repeated-context costs substantially, while batch processing can change the economics of workloads that tolerate a 24-hour service level. Rate limits, time to first token, throughput, and P95 latency, the response time below which 95 percent of requests complete, all belong in the same decision record.
What Still Requires Independent Verification
Tool use, structured output, and long-context behavior should be tested directly. A model may look strong on a coding benchmark and still choose the wrong tool, generate invalid JSON, or lose key details in a lengthy schema-driven output.
Context windows also need workload-specific testing. The supplied June 30 snapshot lists a 2-million-token Sonnet 5 option under a specified header and a 1-million-token window for Opus 4.8. Nominal context capacity does not establish reliable retrieval across the full context. Anthropic reported a 68.1% GraphWalks F1 result for Opus 4.8 at one million tokens, but an equivalent independently established Sonnet 5 result was not available in the supplied material.
For safety-sensitive or regulated workflows, add explicit failure tests. Anthropic's Sonnet 5 safety evaluation described somewhat higher rates of misaligned behavior than Opus 4.8 in the evaluated settings. Treat that as a reason to define and test unacceptable behavior, not as a reason to infer performance in your own environment.
Use Cost per Accepted Outcome, Not Token Price, as the Deciding Metric
Token price is an input. Cost per accepted outcome is the decision metric: the total cost of delivering one result that meets a predefined quality gate.
A simple model is: model spend + retry spend + correction labor + escalation cost + operating overhead, divided by accepted outputs. The numbers become meaningful only after the team defines accepted.
Count Retries, Corrections, Review, and Escalation
For a code patch, acceptance might require a passing test suite and no substantive review changes. For a content workflow, it might mean approval with light editing. For a legal workflow, it might mean no invented citations or missed controlling authority. The definition must fit the workflow, not the model.
Now record the hidden costs. Retries matter when output is malformed or a tool call fails. Corrections matter when reviewers rewrite or restructure work. Escalation matters when Sonnet 5 attempts a difficult task and the fallback is a second run on Opus 4.8. A 15-minute review at a $100 hourly rate adds $25 to each output, which can outweigh a meaningful token-price difference.
Separate One-Off Hard Problems From Daily Production Volume
A complex architecture decision or a repository-scale refactor may justify Opus 4.8 even when it is not the default. Volume is low, the failure cost is high, and the downside of a premium call is bounded.
High-volume workloads have a different equation. Customer-facing agents, extraction pipelines, routine code review, and content generation can accumulate millions of outputs quickly. When Sonnet 5 reaches the accepted-output threshold, a lower per-token price and faster response profile can change the total cost of ownership materially. Run these calculations separately rather than averaging the entire portfolio into one model choice.
Choose by Workload Instead of Naming a Universal Winner
A single organization can reach different rational answers for different workload classes. Begin with a simple operating hypothesis, then replace it with measured performance:
- Repository-scale agentic coding: trial Opus 4.8 where late-run failures and reviewer workload carry a high cost.
- High-volume customer agents: trial Sonnet 5 where response quality and P95 latency meet the service target.
- Structured extraction and summarization: trial Sonnet 5 only after schema validity and acceptance rate stay within defined gates.
- High-risk domain workflows: trial Opus 4.8 where safety and accuracy thresholds are tighter, with a hard escalation path for any serious failure.
The routing rules should be simple enough to explain and inspect.
Where Opus 4.8 May Retain a Premium Role
Opus 4.8 may retain a premium role in work where the evidence shows a meaningful outcome difference: complex multi-step coding, difficult agentic workflows, or high-risk work where a missed error has a large cost. Anthropic also presented Dynamic Workflows in Claude Code as an Opus 4.8 research preview for certain plans, which can matter for teams evaluating codebase-scale workflows.
Keep the model in these roles only when the quality differential appears in your task-weighted evaluation. A premium tier is defensible when it lowers failure and review cost enough to exceed the price difference, not when it merely looks stronger in a general comparison.
Where Sonnet 5 May Become the Better Default
Sonnet 5 becomes a plausible default where complexity is bounded, volume is high, and a reviewer or deterministic validation step catches the remaining errors. Customer-facing chat, production coding assistance with human review, document extraction, and content generation are credible candidates once they pass defined quality and latency gates.
The introductory and standard pricing levels make that test worth running. But tokenizer behavior, caching, rate limits, third-party platform pricing, and task-specific retries can change the apparent saving. Use actual traces before assigning Sonnet 5 to the majority of traffic.
When a Routed Two-Model Policy Beats an All-or-Nothing Switch
A model-routing policy can reserve Opus 4.8 for complex or sensitive tasks while placing routine volume on Sonnet 5. Useful routing signals include task type, expected tool-call depth, domain sensitivity, required output length, and prior failure patterns.
Routing also introduces a new failure mode. A poor classifier can send a hard task to Sonnet 5, pay for an unsuccessful run, and then pay again for Opus 4.8. Keep the first policy rules-based, trace every route decision, and revalidate routing thresholds when either model changes.
Turn the Comparison Into a Model Policy, Not a Permanent Verdict
The durable output is not a permanent model verdict. It is a policy that assigns workload classes, records acceptance criteria, defines routing and escalation, names an operational owner, and triggers revalidation after a major release, price change, or quality decline.
Start with one 30-day task-weighted evaluation. Keep Opus 4.8 where the premium buys a measurable reduction in failure or review cost. Let Sonnet 5 take the workload classes where it clears the same bar with lower cost per accepted outcome or stronger latency. Revisit the policy whenever the underlying conditions change.
Just published



