Trusted by Market Leaders in Education, Travel, Finance and E-commerce since 2007





We put excellence, value and quality above all - and it shows






A Technology Partnership That Goes Beyond Code

“Arbisoft has been my most trusted technology partner for now over 15 years. Arbisoft has very unique methods of recruiting and training, and the results demonstrate that. They have great teams, great positive attitudes and great communication.”











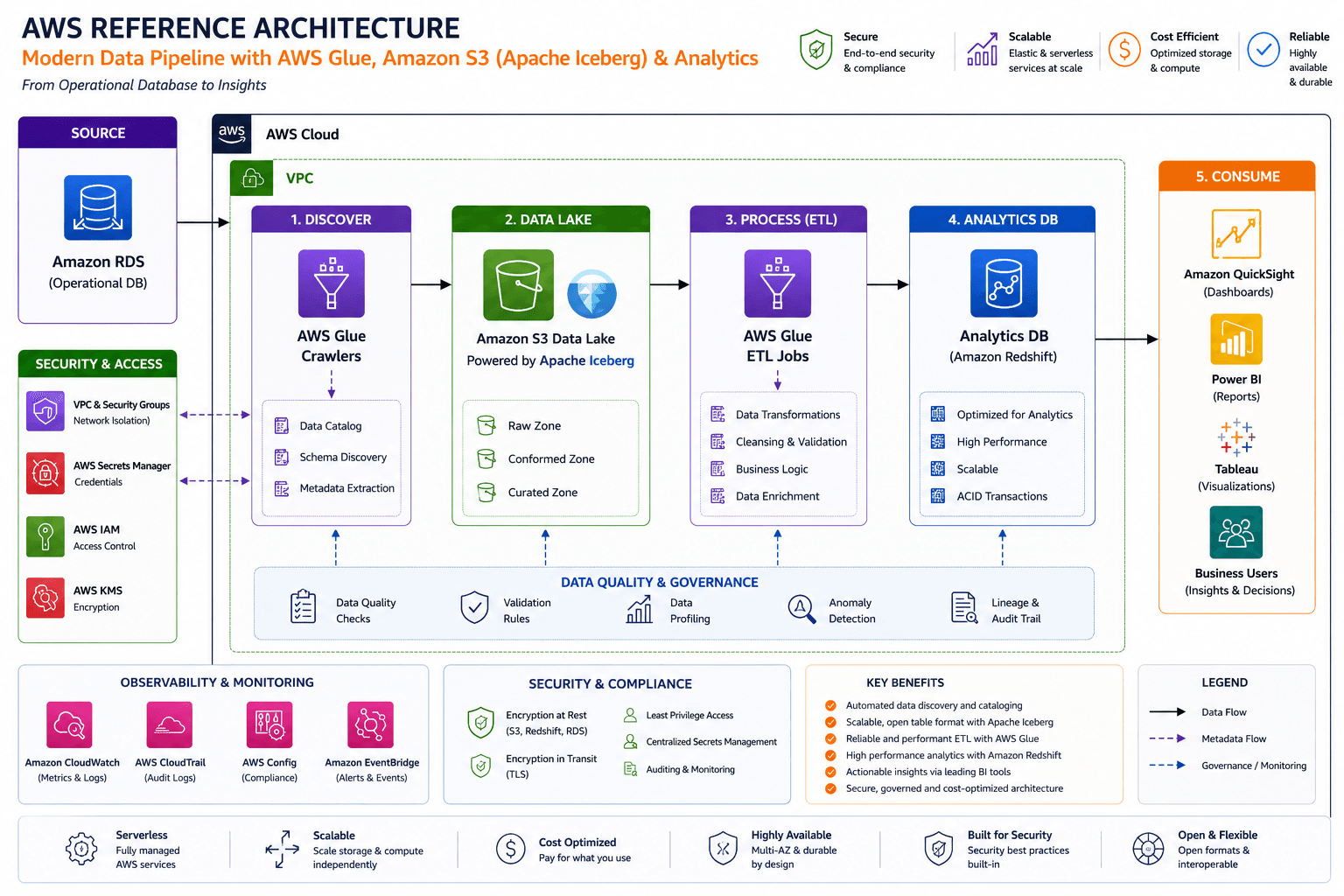
Optimizing AWS Glue ETL Performance: Achieving High-Efficiency Data Transformations Using Apache Iceberg


This technical deep dive explores the architectural evolution from a legacy direct-connect ETL model to a modern, scalable data lakehouse leveraging Amazon S3 and Apache Iceberg for optimized performance and reduced operational overhead.
Introduction
Many data architectures begin with a straightforward pattern: extracting data from production OLTP databases, applying transformations via AWS Glue, and loading results into a reporting downstream. While effective for small datasets, this approach inevitably faces scalability constraints as data velocity and volume increase.
In our experience, we reached a critical inflection point where ETL runtimes degraded significantly. The direct-query model introduced unsustainable read pressure on production systems, impacting both user experience and data freshness.
To address these challenges, we decoupled our extraction and transformation layers by implementing a robust data lake layer based on the Apache Iceberg table format, hosted on Amazon S3.
The Original Architecture
The legacy architecture relied on AWS Glue jobs establishing direct JDBC connections to production MySQL instances. While this simplified early development, it created tight coupling between analytical workloads and operational database performance.

The Problems We Faced
Performance Bottlenecks
High-frequency ETL queries on massive tables saturated database I/O, leading to several critical issues:
- Extended ETL Runtimes: Jobs consistently exceeded 7–8 hours due to throttling and concurrency issues.
- Redundant Extraction: Multiple concurrent workflows query identical datasets, multiplying resource consumption.
- Systemic Latency: High I/O wait times on production instances threatened application stability.
Operational Overhead
Data pipeline fragility necessitated extensive manual intervention, typically consuming 3–5 hours of engineering time daily to resolve timeout failures and cascading workflow delays.
- Frequent Glue job failures
- Cascading workflow delays
- 3–5 hours of manual intervention daily
Scalability Challenges
The architecture lacked a dedicated storage layer between extraction and transformation workloads.
Phase 1 Solution: The "Load Once, Transform Many" Pattern
The core objective of remediation was to decouple the high-pressure analytical workloads from the production OLTP database. The legacy model suffered from "tight coupling," where every ETL job performed direct JDBC reads, causing severe resource contention and extended runtimes (7–8 hours).
We introduced a Data Lakehouse layer using Apache Iceberg on Amazon S3. This shifted the architecture from a direct-connect model to an ingestion-first model.
Key Technical Enhancements:
- Decoupling via Centralized Ingestion: By introducing a dedicated Glue "Ingest" job, the production database is queried only once to extract the full dataset. This data is then persisted as Apache Iceberg tables on S3, which becomes the single source of truth for all downstream transformation jobs.
- Performance Optimization: Subsequent ETL workflows no longer query the production database. They operate exclusively against the S3 Iceberg tables. This isolation eliminated the I/O saturation on the MySQL production instance, drastically improving application stability and data freshness.
- Full-Refresh Strategy: Given the project time constraints, the initial implementation utilized a full table reload on each run. While not the most efficient in terms of storage bandwidth, it provided immediate stability by offloading read pressure from the production database.
Results and Impact
- Operational database: Now protected from heavy analytical traffic. It serves only the initial ingestion job, significantly reducing I/O wait times.
- Glue Ingest Job: Acts as the gateway. It executes the extraction process and manages the write-to-Iceberg operation.
- Storage Layer (S3 + Apache Iceberg): This is the "Data Lake" tier. Apache Iceberg provides ACID compliance and schema evolution support, which ensures that even though tables are reloaded/overwritten during Phase 1, the downstream ETL jobs can read consistent snapshots of the data.
- Transformation Layer (Glue): Decoupled from the source, these jobs now read from the Iceberg tables on S3. Since S3 I/O is typically faster and more scalable than direct MySQL JDBC reads, job runtimes were reduced from 8 hours to ~2.5–3 hours.
What’s Next: Phase 2
Phase 1 established the foundation for a scalable lakehouse architecture. Phase 2 focuses on incremental processing and advanced optimization.
- Incremental loading using watermarking and CDC
- Upsert and merge support inside Iceberg tables
- Iceberg table partitioning and schema evolution
- Incremental writing to target database
Just published



