Trusted by Market Leaders in Education, Travel, Finance and E-commerce since 2007





We put excellence, value and quality above all - and it shows






A Technology Partnership That Goes Beyond Code

“Arbisoft has been my most trusted technology partner for now over 15 years. Arbisoft has very unique methods of recruiting and training, and the results demonstrate that. They have great teams, great positive attitudes and great communication.”











How Enterprises Can Use Deep Learning to Drive Real Business Value: Practical Roadmap


In 2024, 78% of organizations said they were already using AI, up from just 55% the year before. That’s one of the fastest adoption curves in enterprise tech history, and it shows how quickly leaders are moving from experimentation to execution.
Deep learning is at the center of this shift. The global market for deep learning solutions and the supporting MLOps ecosystem is expanding at double-digit CAGRs, with forecasts putting both in the multi-billion-dollar range by 2030. Companies are piloting models and building scalable pipelines, production-ready systems, and governance frameworks around them.
And the results are clear. McKinsey’s 2025 AI survey found that organizations capturing real value from generative AI and deep learning are rewiring entire processes, not just automating tasks. These firms are reporting measurable gains in revenue growth, efficiency, and time-to-market.
For market leaders, this is more about staying competitive than just automating tasks. The enterprises that treat deep learning as core infrastructure, not an experiment, are the ones setting the pace for their industries.
Why Deep Learning
Deep learning is different from traditional machine learning because it doesn’t rely on hand-crafted features. Instead, it learns patterns end-to-end from raw data, whether it’s text, images, audio, or sensor streams. That ability to automatically discover what matters is why deep learning has become the backbone of modern enterprise AI.
For businesses, the outcomes are tangible. In customer service, deep learning powers intelligent chatbots and voice systems that handle thousands of queries instantly, cutting costs while keeping customers satisfied. In operations, it enables predictive maintenance, helping manufacturers anticipate equipment failures and reduce downtime.
For retailers and e-commerce platforms, it drives hyper-personalization. From recommending the right product at the right time, to boosting conversion rates, and to the average order values. Banks and insurers are using it to process and analyze documents in seconds, while travel and hospitality companies are creating new revenue streams with AI agents that upsell services in real time.
According to Stanford’s AI Index 2025, 78% of organizations were actively using AI in 2024, up sharply from 55% in 2023. That adoption curve is being fueled by the rapid maturity of deep learning models, accessible infrastructure, and an expanding ecosystem of enterprise-ready tools. Global market forecasts also predict double-digit growth in deep learning and MLOps solutions through the decade, reflecting the demand for scalable, production-grade AI.
For market leaders, deep learning is a proven driver of automation, prediction, personalization, and revenue growth. The organizations that build it into their core processes are gaining a competitive edge and reshaping how industries operate.
Is Deep Learning the Right Tool for Your Business?
Not every business problem needs deep learning. The real question for leaders is when it adds unique value, and well, when it doesn’t.
Deep learning works best when data is abundant and complex. If you have large labeled datasets or access to semi/unlabeled data that can be tapped with self-supervised methods, Deep Learning becomes powerful. It’s the right fit for unstructured data, that is, images, audio, text, or graphs, where traditional approaches fall short. That’s why it’s driving breakthroughs in customer interactions, fraud detection, and industrial automation.
But Deep Learning is not always the answer. If your dataset is small, if you need transparent and fully interpretable rules, or if you’re building a quick MVP with minimal infrastructure cost, then simpler models often deliver faster value. In fact, many enterprises blend both approaches, using Deep Learning where complexity demands it, and lighter models where speed and clarity matter more.
A quick decision checklist helps:
- Do you have the data scale to train and sustain DL models?
- What are your latency requirements? real-time or batch?
- How critical is interpretability for regulators or internal stakeholders?
- Are there compliance risks tied to how the model makes decisions?
- What’s the cost profile? Both infrastructure and talent?
Data Strategy & Foundations
Deep learning starts with data, and the difference between a successful AI program and a stalled one often comes down to how well enterprises manage it. Models are only as good as the pipelines, governance, and strategy that feed them.
1. The first step is a data audit. Enterprises need a clear inventory of both structured and unstructured data: CRM records, IoT sensor streams, PDFs, emails, call transcripts, images, and videos. Checking labels, cleaning noise, and maintaining lineage ensures that models learn from reliable, traceable sources. Without this, even the most advanced models produce inconsistent results.
2. Next comes data operations. Modern enterprises use ingestion pipelines and schema registries to standardize how data flows. Technologies like Apache Iceberg, Databricks, and Delta Lake give reliability with ACID transactions and time travel for datasets. Parquet or Feather formats, combined with versioning systems, make datasets reproducible. This avoids the all-too-common problem of “data drift,” where models train on one version and infer on another.
3. Labeling strategy is where efficiency and accuracy intersect. Traditional manual labeling is too slow and expensive at scale. That’s why leaders are adopting active learning, weak supervision, and synthetic data generation for computer vision. Tools like Label Studio make it easier to manage workflows, while human-in-the-loop review handles edge cases that models struggle with.
4. No strategy is complete without privacy and compliance. With regulations tightening across regions, enterprises need strong controls: anonymization of sensitive fields, purpose-limited logging, and clear retention policies. This is about maintaining trust with customers and regulators.
5. Finally, feature stores such as Feast are becoming a standard. They let teams share, reuse, and serve features consistently across training and production. That means faster iteration, less duplication, and fewer errors when models scale.
How To Choose the Right Deep Learning Architectures and Models?
To better understand how deep learning is transforming enterprises today, let’s break down its key applications across industries and the tangible value they bring.
Use Case | Best Model Type | Example Enterprise Application |
| Text, documents, knowledge | Transformers / LLMs | Automated customer support, RAG-powered search, code copilots |
| Images & video | CNNs / Vision Transformers (ViTs) | Manufacturing defect detection, medical imaging, retail visual search |
| Graph-structured data | Graph Neural Networks (GNNs) | Fraud detection in finance, supply-chain optimization, network security |
| Forecasting & predictions | Time-Series Models (TFT, N-BEATS) | Demand forecasting in logistics, pricing in energy, financial risk modeling |
| Synthetic content & design | Diffusion Models | Product design, content generation, synthetic training data creation |
| Mixed / hybrid enterprise tasks | Hybrid Stacks (pre-trained + task heads) | Enterprise search, personalized recommendations, document classification |
Infrastructure & Deployment Patterns
Enterprises adopting deep learning are moving away from one-size-fits-all infrastructure. Instead, they’re choosing deployment models that match performance, privacy, and cost requirements.
Cloud-first
Cloud-first approaches remain the backbone for training. With hyperscalers offering access to GPU and TPU clusters, teams can train large-scale models faster and more affordably. In fact, Gartner predicts that by 2026, over 70% of enterprises will rely on cloud-native AI infrastructure for training workloads. Centralized cloud environments are ideal when datasets are massive and collaboration is distributed.
Edge
Edge inference is growing rapidly, especially in healthcare, retail, and manufacturing. Running models directly on devices reduces latency and protects sensitive data. Edge AI is no longer niche. IDC projects that over 55% of new enterprise applications will include edge inference by 2027. Lightweight techniques like quantization and pruning allow models to run efficiently on constrained hardware without losing critical accuracy.
Hybrid
Hybrid deployment is now the sweet spot for many organizations. Models are trained in the cloud, but inference is split. The real-time, privacy-heavy tasks stay on the edge, while batch or less time-sensitive tasks run in the cloud. This balance helps enterprises deliver low-latency experiences while still benefiting from the scale of cloud resources.
Optimization
Optimization has also become a key differentiator. Model compression through pruning, quantization, and distillation is standard practice. Enterprises are adopting high-performance inference engines like ONNX Runtime, TensorRT, TFLite, and OpenVINO to cut inference costs while boosting speed. McKinsey notes that companies leveraging optimized inference pipelines can reduce AI infrastructure spend by up to 30% annually.
Cost control
The cost control strategies are becoming smarter. Spot instances, autoscaling inference clusters, and serverless GPU offerings are helping enterprises align compute costs with actual usage. Leaders who embrace these approaches are not just scaling deep learning; they’re doing it sustainably, both financially and operationally.
MLOps: From Experiments to Production
Deep learning success doesn’t end at building a model. The real challenge is taking it from experiments to production and keeping it reliable at scale. MLOps is now the backbone of that journey.
1. Experiment Tracking & Reproducibility
- Tools like Weights & Biases, MLflow, and Neptune track datasets, parameters, and results in one place.
- Reduces duplication of work and ensures reproducibility across teams.
- In 2025, centralized experiment management has become the norm for high-performing AI teams.
2. CI/CD for Models
- Automated pipelines validate models before release.
- Canary and blue-green rollouts test new models in production without risking downtime.
- Automatic rollback protects customer experience if performance drops.
- Enterprises are cutting release cycles from months to weeks, or even days.
3. Monitoring & Observability
- Once deployed, models face data drift and concept drift.
- Enterprises now set SLOs for prediction accuracy, latency, and GPU utilization.
- Modern observability tools detect performance degradation and trigger retraining automatically.
4. Feature Stores for Consistency
- Guarantee the same transformations in training and production.
- Prevents silent model failures caused by inconsistent pipelines.
- Encourages reusable libraries of validated features, reducing deployment time.
5. Governance & Auditability
- With rising regulation in finance, healthcare, and public services, governance is critical.
- Model cards, lineage tracking, and compliance-ready logging ensure transparency.
- Builds trust with both regulators and customers by documenting decision-making.
The global MLOps market is set to grow from USD 1.41B (2023) to USD 13.47B (2032). That’s a 28.2% CAGR. For market leaders, MLOps is a core capability for scaling AI responsibly.
Risk, Ethics & Governance
As enterprises scale deep learning, risk management has become a core priority. Models that drive value can also create exposure if not handled responsibly.
Explainability
Techniques like SHAP, LIME, and counterfactual analysis now help businesses justify model decisions. This is something regulators in finance and healthcare increasingly demand.
Fairness
Bias is another pressing issue. PwC reports that in 2025, 76% of executives view AI fairness as critical to adoption, pushing companies to invest in dataset audits, fairness metrics, and adversarial testing to avoid inequities and maintain trust.
Security
Threats such as model poisoning and prompt injection can quietly undermine systems. Robustness testing and adversarial defense are becoming part of the standard enterprise playbook.
Governance
With new AI regulations rolling out across the EU, US, and Asia, practices like audit logs, lineage tracking, and human-in-the-loop oversight are shifting from optional to mandatory.
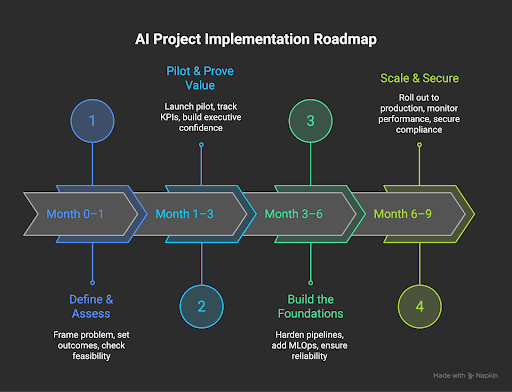
Implementation Roadmap
Enterprises don’t need multi-year AI bets to see results. A structured 6–9 month roadmap can deliver value fast while laying the groundwork for scale. Here’s how:
Month 0–1: Define and Assess
Start with problem framing and value hypotheses. Identify the business outcome you want to impact—whether it’s reducing churn, automating a process, or improving forecasting accuracy. Run a data inventory and feasibility check to ensure the right inputs exist. McKinsey notes that projects aligned to a clear business metric are 2x more likely to deliver measurable ROI.
Month 1–3: Pilot and Prove Value
Launch a small pilot using transfer learning or model prototypes. Keep the scope narrow but measurable and target KPIs that prove the concept works. Collect early performance metrics and user feedback. Successful pilots build executive confidence and help secure buy-in for further investment.
Month 3–6: Build the Foundations
Once proof of value is established, shift to hardened pipelines and MLOps practices. Add experiment tracking, feature stores, and dataset versioning to ensure repeatability. Introduce human-in-the-loop reviews for edge cases and compliance-sensitive outputs. This phase is critical to move beyond experimentation and ensure enterprise reliability.
Month 6–9: Scale and Secure
Move to production rollout with monitoring and optimization in place. Track drift, latency, and resource utilization in real time. Secure compliance sign-off with audit logs and governance practices. At this point, develop a business case for scale, highlighting ROI, operational savings, and new revenue opportunities. IDC reports that organizations with structured AI adoption roadmaps are achieving 20–30% faster time-to-value compared to ad-hoc approaches.
Micro-Implementations to Improve and Scale
Big AI projects can feel overwhelming. The smarter approach is to start with micro-implementations that target use cases that prove value quickly and scale later. Here are four examples where deep learning is already driving measurable impact.
Customer Support Automation
A retrieval-augmented generation (RAG) system with LLMs can instantly pull answers from a company’s knowledge base, handling routine queries with human backup for complex cases. Enterprises report up to 40% faster response times and higher CSAT scores when combining automation with escalation paths.
Visual Quality Inspection
Manufacturers are fine-tuning vision transformers to spot defects in real time on assembly lines. The results are clear: fewer false negatives, lower scrap rates, and reduced manual inspection costs. Deloitte estimates that AI-driven quality control can cut defect-related costs by 20–30%.
Predictive Maintenance
Sensors on equipment feed into time-series forecasting models like TFT and ensemble networks to predict failures before they happen. Predictive analytics for enterprises has seen downtime reductions of up to 25%, saving millions annually in industries like aviation, energy, and heavy machinery.
Document Ingestion & Contract Analytics
Legal and financial teams are leveraging NER (named entity recognition), relation extraction, and retrieval models to process contracts at scale. What once took days now takes hours. Companies using AI-driven document workflows are reporting contract review times cut by 60%, freeing experts for higher-value tasks.
Final Takeaway
Deep learning has moved past the hype cycle. It is more about enterprise infrastructure now. The companies winning today aren’t just automating tasks; they’re redesigning processes, unlocking new revenue, and setting higher standards for customer experience.
To move forward, start with the right problems, build strong data foundations, choose architectures that fit the task, and deploy with scale and responsibility in mind. Add in MLOps discipline, governance, and targeted micro-implementations, and you have a roadmap that delivers measurable value in under a year.
Leaders who act now will define the benchmarks their industries follow. Deep learning is here, it’s enterprise-ready, and the real differentiator is how boldly and responsibly you put it to work.
Just published



