Trusted by Market Leaders in Education, Travel, Finance and E-commerce since 2007





We put excellence, value and quality above all - and it shows






A Technology Partnership That Goes Beyond Code

“Arbisoft has been my most trusted technology partner for now over 15 years. Arbisoft has very unique methods of recruiting and training, and the results demonstrate that. They have great teams, great positive attitudes and great communication.”











Six Months After the Mythos Leak: How Claude Fable 5 Lived Up to the Hype


The Leak Promised a Myth. Six Months Later, the Evidence Is Messier
The Mythos Leak did not behave like an ordinary product rumor. It started with a concrete exposure: Fortune reported that Anthropic had accidentally left nearly 3,000 unpublished internal assets publicly accessible through a content management system misconfiguration. Among them was a draft post about an unreleased model called Claude Mythos, internally codenamed Capybara.
That detail matters because the hype did not come only from fan interpretation. Anthropic confirmed the exposure, described Mythos as a "step change" in artificial intelligence performance, and acknowledged early customer testing.
The evidence is still messier than the ‘myth’ (pun intended). Claude Fable 5, the first publicly accessible Mythos-class model, launched on June 9, 2026. What this means is there isn’t a true six-month public usage record to evaluate, instead we’re contending with a longer hype cycle, a short launch window, official performance claims, selected early-access evidence, and early independent tracking.
The fair test, then, is not whether Claude Fable 5 is impressive but whether its verified performance matches the expectations the leak created.
What the Mythos Leak Actually Led People to Expect
The Mythos Leak led people to expect more than an incremental Claude upgrade. The leaked draft reportedly framed Mythos as "by far the most powerful AI model" Anthropic had developed, with higher scores than Claude Opus 4.6 in coding, academic reasoning, and cybersecurity benchmarks.
The most consequential claim was about cyber capability. The draft reportedly said Mythos was "currently far ahead of any other AI model in cyber capabilities" and warned of models that could exploit vulnerabilities faster than defenders could respond. That language moved the story beyond normal model benchmarking. It implied a system powerful enough to require special caution.
The leak also suggested enterprise ambition. Separate exposed material referenced an invite-only CEO summit in Europe, reinforcing the view that Mythos was being positioned for high-value, high-risk deployment rather than casual consumer use.
The Claims that Mattered Most
Four expectations shaped the Claude Fable 5 narrative.
- Mythos was expected to represent a new capability tier above Opus, not a simple version bump.
- It was expected to show major gains in coding and reasoning.
- It was expected to have unusual cybersecurity capacity.
- It was expected to arrive through a controlled rollout because Anthropic viewed the model as too risky for ordinary release.
Claude Fable 5 partly confirms that framing. It is presented as a Mythos-class public model, not merely another Opus release. It also shows strong coding and agentic performance in the launch evidence. But the highest-stakes Mythos claims, especially around cyber and life sciences capability, remain tied to restricted access through Project Glasswing and Mythos 5, not the public Fable 5 model.
That distinction is the blog’s premise: Fable 5 can validate the capability jump without validating every Mythos claim.
Where speculation filled the gaps
The leak did not provide a public model card, a complete benchmark methodology, or reproducible third-party testing. That left room for speculation.
Some public discussion inferred broad multimodal superiority, even though concurrent reporting centered more on coding, reasoning, and cyber capability. Other discussion assumed Mythos-level capability would be available at Opus-like pricing, despite leaked material reportedly saying the model was expensive to run. Some commentary also conflated the Mythos model leak with a separate Claude Code source-code exposure, creating a broader narrative of Anthropic dysfunction.
The result was a familiar AI hype pattern: a partial document became a complete story. The missing pieces were filled with assumptions, and those assumptions became part of what Claude Fable 5 would later be judged against.
How Claude Fable 5 Performed When the Hype Met Daily Use
Claude Fable 5’s strongest evidence is in coding, agentic workflows, and complex reasoning tasks. Anthropic’s launch materials and independent trackers report a score of 80.3 percent on SWE-Bench Pro, ahead of Claude Opus 4.8 at 69.2 percent, GPT-5.5 at 58.6 percent, and Gemini 3.1 Pro at 54.2 percent.
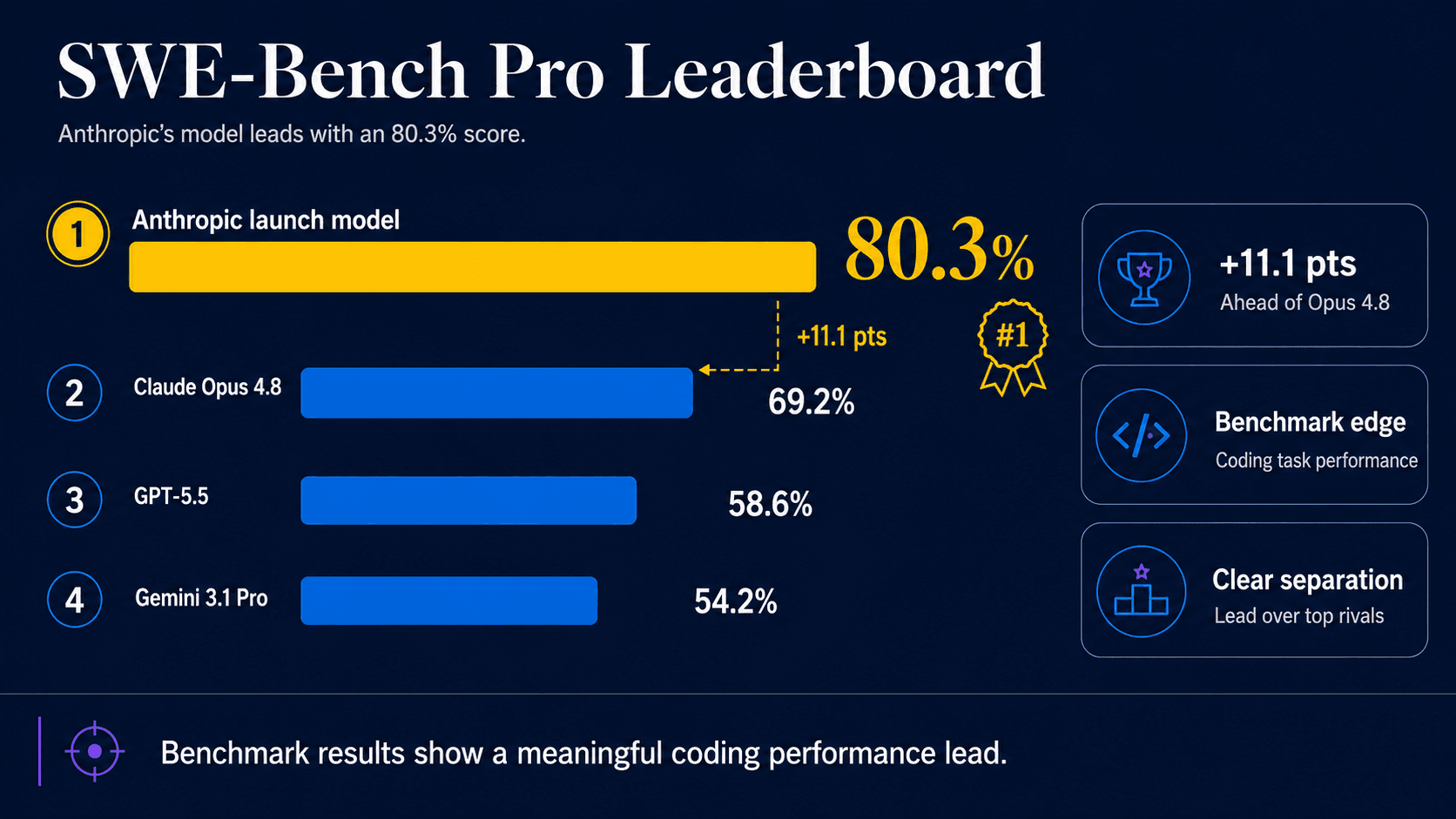
On FrontierCode Diamond, a difficult production-codebase evaluation, Fable 5 reportedly scored 29.3 percent, compared with Opus 4.8 at 13.4 percent and GPT-5.5 at 5.7 percent. BenchLM placed it second overall among 123 models, with especially strong Agentic and Coding category scores.
Those results support the idea of a step change. They do not settle the whole question.
Reasoning, Coding, and Complex Task Performance
The coding evidence is hard to dismiss. The FrontierCode Diamond score more than doubles Opus 4.8, while the SWE-Bench Pro result points to meaningful improvement on contamination-resistant software tasks. Independent early-access evaluations add detail: Hex reported that Fable 5 crossed 90 percent on its complex analytics benchmark, and IMC reported strong performance on trading-analysis evaluations.
Developer-platform evidence points in the same direction. GitHub made Claude Fable 5 generally available for Copilot and reported that it completed equivalent autonomous coding workflows with fewer tool calls and lower token consumption than prior Opus-tier models. Cursor described Fable 5 as state of the art on CursorBench, especially for long-horizon problems.
But benchmark interpretation needs caution. SWE-bench-style evaluations have documented contamination concerns, and high benchmark scores can diverge from real-world codebase performance. SWE-Bench Pro was designed to reduce those risks, which makes Fable 5’s result more credible than a standard public benchmark score. Still, independent replication matters.
Multimodal, Context, and Workflow Reliability
Fable 5 launched with text and image input, a context window above 1 million tokens, and output support up to 128,000 tokens per request. Anthropic described better vision capability and stronger computer-use performance, including an 85.0 percent score on OSWorld-Verified.
The independent picture is more mixed. BenchLM gave Fable 5 a weaker relative ranking in multimodal and grounded tasks than in coding or agentic tasks. That does not mean the model is weak. It means the clearest delivery is not across every category. Fable 5 appears strongest where the Mythos leak was most specific: coding, reasoning, and long-horizon agentic work.
Long context also needs a practical caveat. A 1 million token window is not the same as reliable reasoning across 1 million useful tokens. Anthropic’s own documentation notes long-context failure modes such as context pollution, goal drift, memory corruption, and decision inaccuracy. For teams using Fable 5 in large codebases or document-heavy workflows, the right test is not maximum context length. It is whether the model stays accurate near the middle and end of a long task.
Speed, Cost, Access, and Product Fit
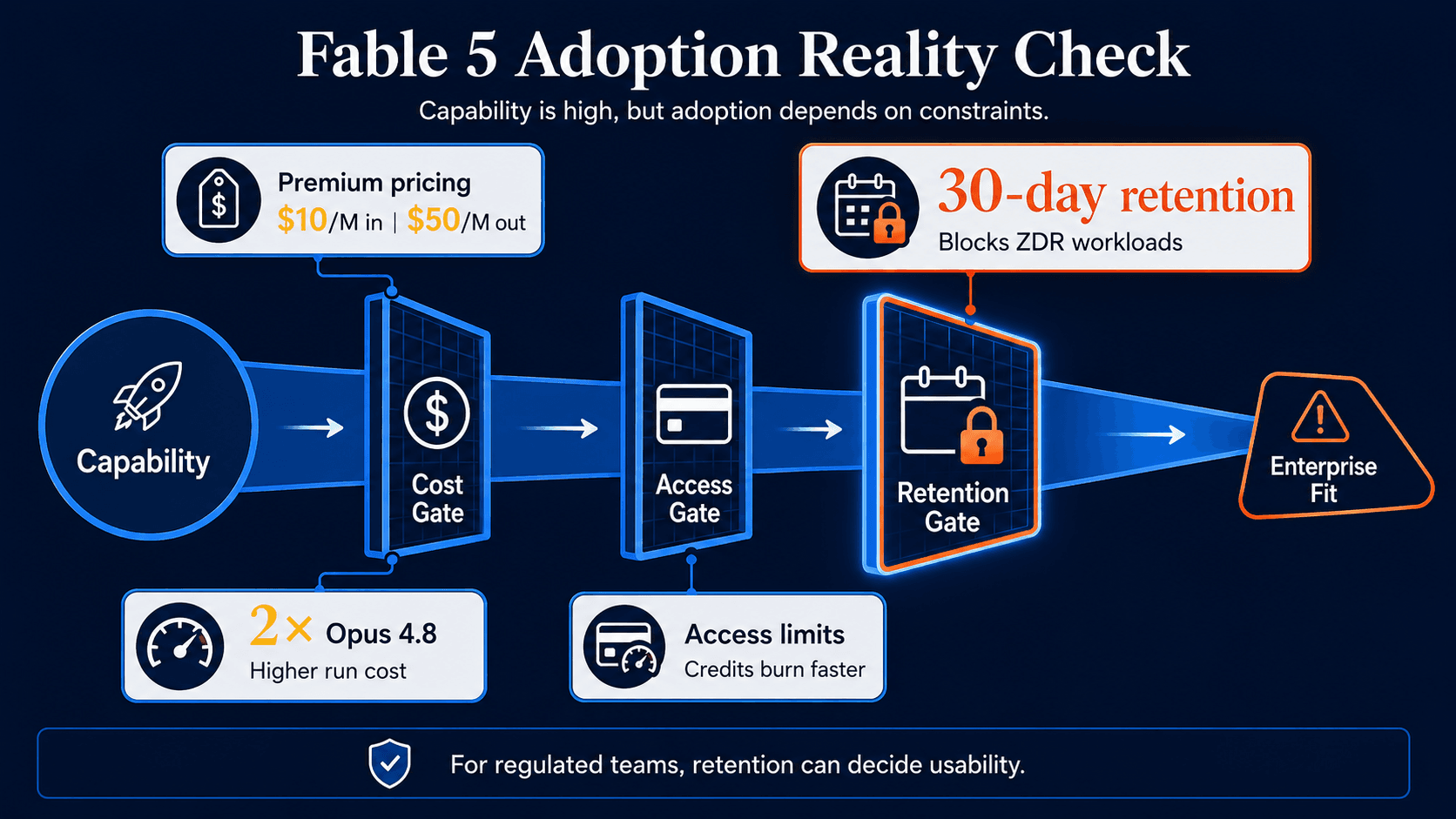
Claude Fable 5 costs $10 per million input tokens and $50 per million output tokens, double the listed Opus 4.8 pricing. That confirms the leak’s suggestion that Mythos-class capability would be expensive to run.
Access also complicates the adoption story. Fable 5 was initially included for Pro, Max, Team, and seat-based Enterprise plans, but Anthropic described that inclusion as time-limited while it managed capacity. For subscription users, the model’s higher credit consumption quickly became part of the practical experience.
The largest enterprise constraint is data retention. Fable 5 traffic is subject to a mandatory 30-day retention policy, unlike other Claude API models that can operate under Zero Data Retention agreements. For regulated legal, financial, healthcare, and security workloads, that is not a minor footnote. It can decide whether the model is usable at all.
The Strongest Case That Claude Fable 5 Delivered
The strongest case for Fable 5 is simple: the model delivered where the leak created the most measurable expectations.
Coding performance improved sharply. Agentic workflow performance appears meaningfully stronger. Early-access examples, while not neutral in the strictest sense, are specific enough to matter. Stripe’s Ruby migration case is the clearest: Anthropic cited a 50-million-line migration completed in one day, compared with an estimated team effort of two months. That is a concrete workflow claim attached to a named organization and task.
Other examples point in the same direction. Hex reported a large jump on long-running analytics tasks. Hebbia’s finance evaluation placed the model strongly in senior-level reasoning. GitHub and Cursor both framed Fable 5 as expanding what developers can hand to agents.
A model does not need to satisfy every rumor to justify some of the hype. On coding and long-horizon agentic work, Fable 5 looks like a real break from the prior Claude tier.
Where The Model Changed User Behavior
The most credible behavior-change evidence comes from developer platforms. GitHub Copilot availability put Fable 5 directly into mainstream coding workflows. Cursor’s claims about long-horizon tasks suggest the model is not only answering harder prompts but changing what kinds of work users attempt with AI agents.
That is a different kind of evidence than social media excitement. It shows workflow integration, not just launch chatter.
Still, durable adoption is not yet proven. The model launched days before the research window captured in the source material. Teams may test Fable 5 immediately and still revert if cost, retention, latency, or reliability do not fit production constraints. A launch spike is not the same as sustained use.
The Case Against Calling It a Full Payoff
The skeptical case starts with the split between Mythos 5 and Fable 5. The leak described Mythos-level capability. The public received Fable 5, a safer and more constrained Mythos-class model. That may be responsible product design, but it means the public model cannot fully validate the leaked claims.
The cyber capability claim is the clearest example. The leak’s most dramatic language concerned cybersecurity. Yet the full-capability Mythos 5 remains restricted through Project Glasswing. Public users can test Fable 5’s coding and reasoning strength, but not the complete cyber capability that originally moved markets.
Safety filters add another layer. Early community testing reported cases where biology-adjacent prompts triggered conservative fallback behavior. Anthropic has acknowledged that some classifiers can catch harmless requests. That is not evidence of poor underlying model intelligence, but it is part of real user experience.
Benchmark Wins Did Not Settle The Practical Question
Benchmarks matter because they provide comparable evidence. They also compress messy behavior into clean numbers.
Fable 5’s coding scores are significant, especially on more controlled evaluations. But benchmark results still depend on task selection, harness design, contamination controls, and whether the test resembles actual user workflows. A model can score well on repository tasks and still struggle with ambiguous product requirements, messy legacy code, long-running debugging, or tool failures.
The public should treat Fable 5’s benchmarks as strong evidence of capability, not universal proof of fit. For serious use, the practical test is narrower: run the model on representative work, measure rework, review burden, latency, cost, and error severity, then compare it against the current model stack.
The Unresolved Questions After Six Months
Several important questions remain unresolved.
The unauthorized-access report from April 2026 has not been fully closed in public. If unauthorized users accessed Mythos through a third-party vendor, that could complicate the safety-gated rollout narrative.
Enterprise adoption is also unresolved. The data-retention policy was announced at launch, and procurement cycles do not resolve in days. The model may be attractive for finance, law, and complex analysis, but those are also areas where retention requirements can block deployment.
Most importantly, there is no six-month public usage record for Fable 5. There is a six-month-style retrospective on the Mythos hype cycle, but Fable 5 itself is new. Longitudinal evidence on retention, production reliability, and real enterprise deployment will take longer.
What This Retrospective Says About AI Hype Cycles
The Mythos-to-Fable arc shows how AI leaks can become unofficial product launches. Internal language escaped before normal review, and phrases such as "step change" and "far ahead" became public anchors for expectation.
That matters because leaked internal confidence is not the same as verified public capability. Markets, users, and analysts reacted before independent testing could exist. Cybersecurity stocks reportedly fell after the leak because the draft suggested a model that could alter the attacker-defender balance.
The case also shows a new release pattern: restricted frontier capability paired with a constrained public model. Anthropic could preserve access control around Mythos 5 while still releasing Fable 5 as a broadly usable Mythos-class system. That makes evaluation harder. The public can judge Fable 5, but some of the leaked Mythos claims remain inaccessible.
A useful rule for future leaks is to separate four things: leaked claims, official confirmation, independent benchmarks, and sustained workflow adoption. Confusing them is how hype becomes myth.
So Did Claude Fable 5 Live Up to the Myth?
Claude Fable 5 lived up to the hype in coding and agentic work. The benchmark margins over Opus 4.8 and competing frontier models are large, and developer-platform evidence from GitHub and Cursor suggests real workflow expansion. The model looks meaningfully stronger than its predecessors on the tasks that most clearly match the Mythos leak’s capability claims.
It only partly lived up to the broader promise. Multimodal performance appears strong but not category-defining. Long-context capacity is real, but reliability still depends on task structure and context management. Enterprise usefulness is constrained by price, capacity, and mandatory data retention.
It did not fully validate the myth though. The leaked document’s highest-stakes claims concerned unprecedented cybersecurity capability and restricted power. Those claims belong more to Mythos 5 and Project Glasswing than to the public Fable 5 release. Without independent access to the full Mythos model, the most dramatic parts of the leak remain unresolved.
For developers, Fable 5 deserves serious testing on long-horizon coding and agentic workflows. For enterprise buyers, the first question is not benchmark performance. It is whether the retention policy and cost model fit the use case. For analysts, the lesson is sharper: a leak can reveal real capability and still create expectations no public model can fully satisfy.
Claude Fable 5 is real, capable, and in several areas materially better than the Claude models before it. It lived up to some of the hype.
It did not become the myth the leak invited people to imagine.
Just published



