Trusted by Market Leaders in Education, Travel, Finance and E-commerce since 2007





We put excellence, value and quality above all - and it shows






A Technology Partnership That Goes Beyond Code

“Arbisoft has been my most trusted technology partner for now over 15 years. Arbisoft has very unique methods of recruiting and training, and the results demonstrate that. They have great teams, great positive attitudes and great communication.”











Step-by-Step with Transformers: From Seq2Seq Bottlenecks to Cutting-Edge Attention Mechanisms in NLP


Ever been in a room buzzing with chatter, where every voice is trying to say something important? Just think if you could tune in to the whispers amid all that noise. That’s a bit like how modern NLP models work—they sift through layers of language to capture what truly matters.
In this blog, we’re taking a laid-back, step-by-step journey from the limitations of old-school Seq2Seq models to the transformers. Let’s dive in and discover how these smart mechanisms can transform how we understand language.
What is NLP?
NLP stands for Natural Language Processing. You might have heard this a lot, so let’s dive deep into what it actually means.
Natural Language basically refers to human language - the language we use to communicate in our daily lives. Natural language processing, therefore, refers to the understanding, manipulation, and comprehension of human language.
Language Models
One of the major applications of NLP is language models. Their main task is to predict the next word. For example, if I need to complete a sentence, my language model will tell me what will be the next word after ‘my’ in the sentence: “This is my __”.
The basics of predicting the next words stand on unigram, bigram, trigram, .. ngram models which predict the next word based on the previous n words. The base of these models is probability. Predicting the next word is basically what is referred to as text generation. You might have heard a lot about text generation too.
In today’s date we have many powerful models generating text, but have we ever thought about how? Let’s dive a bit into that!
Sequence to Sequence Models
So, let's start with - what is our input and what output do we expect from it?
For NLP our input is mostly natural human language, text to be exact.
We will be following this representation throughout this blog.

Here in the figure, input at each time (of sequence) is a vector, each layer has many neurons. We will represent the entire layer with many neurons as a box.
We will be talking about sequence models here. A few types of sequence models are as follows:
1. One to one:
This model takes one fixed-size input and returns one fixed-size output. Examples can be image classification or part of speech tagging.
2. One to many:
This model uses only one input but outputs a sequence. Examples can be image captioning, which takes a fixed-size image as input and gives a sequence of words as output.
3. Many to one:
This model takes a sequence as input and outputs one word. An example can be sentiment analysis, where a sentence or sequence of words can be classified as either positive, negative, or neutral.
4. Many to many:
The model uses a sequence as input and output a sequence as well. Examples can be machine translation, a sequence of words in French, and an output of a sequence but in English.

Many NLP tasks can be categorized as seq2seq tasks like summarization, dialogue generation, code generation, language translation, etc. We will take the example of language translation to understand further. This task requires converting a sequence in the source language into the target language by keeping the semantic information intact. Goal is:

Now let’s dive into a basic sequence-to-sequence model, which formed the base of the transformers.

In this figure, we can see that a sequence-to-sequence model is composed of two parts. The encoder and decoder. The input sentence is first tokenized and then converted into embeddings, which then go to the encoder, that is in the last hidden layer of the encoder. The whole crux of the input is encoded. This encoded information is given to the decoder, which is responsible for generating the next word (and hence an output sequence).
As seen in the figure, we also give the generated output to the next layer as input. During training, we also give the ground truth at each timestamp to guide the model towards correct generation. This is called teacher training. At each timestamp, a word is predicted.
Argmax is used to predict the most probable word at each timestamp given the previously generated output. This is called the greedy approach. A better approach is to apply beam search. At each timestamp, a track of the most likely words is kept, and the one with the highest score for the generated sequence is kept. It determines the size of the search and is a hyperparameter.
Shortcomings of Seq2Seq Models
The issue with this seq2seq model is that all the information from the start of the sentence till the end is encoded in one layer, thus it is overloaded. This becomes a bottleneck. Apart from that each hidden layer is dependent on the previous one. To cater to these problems, and make the model more parallel rather than sequential, attention was introduced which is the main focus of transformer models.

All about Attention
To understand it better, let's look at this figure below.

The figure shows the main idea of attention. Information bottlenecks in seq2seq models can be removed using attention. At each decoder step we use the dot product of decoder activation and encoder activations to get attention scores. Then softmax of attention scores is taken to turn these values into a probability distribution. This attention distribution is used to calculate the weighted sum of encoder activations. Attention output is used to influence the generation of words at each time step. The attention output is concatenated with decoder activations to calculate the output.
Attention actually allows the decoder to focus on relevant parts in the source input sentence. It helps in resolving the bottleneck issue by removing the reliance on a single vector to capture the whole input sequence. Now the decoder has attention for guidance. It paves the way for a direct connection between the decoder and encoder which helps especially for longer sentences. It also allows us to have interpretability power, by analyzing the attention output we can understand what the decoder was focusing on while predicting a certain target output.
Transformer Model
Let's look at the transformer models closely here.

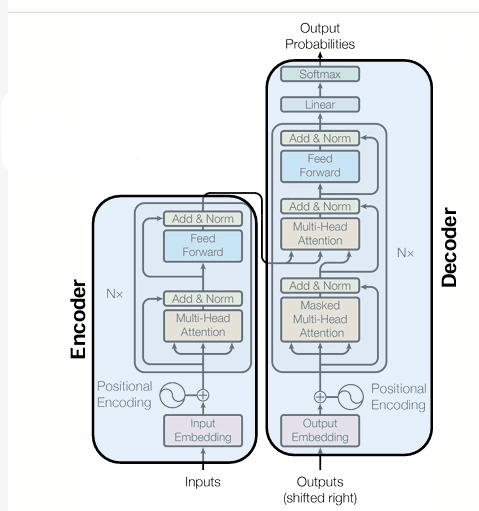
As shown in the figure above, the transformer model has encoder-decoder architecture as well.
The encoder accepts input as text, gives output as word embeddings, uses self-attention, and is bidirectional. The decoder also takes input as words, gives output as a sequence of words, uses masked self-attention, and is unidirectional.
Let’s understand each component separately.

The positional encoder uses a vector that gives context based on the position of words in a sentence. This positional encoding has the same length as the input embeddings for ease of summation. Cosine and sine functions are used to calculate the positional encoding for each word.

In this part of the encoder, self-attention is applied. A linear layer is fully connected without an activation function. Query, key, and value are used to calculate the attention. The similarity between query and key serves as the base for attention.
The query, key and values consist of position-aware embeddings processed by relevant linear layers. Multiple attention heads are learned and each focuses on a particular linguistic aspect. The original transformer paper used 8 attention heads.

As seen from the image, a skip connection is present. So here, position-aware embeddings and the output of multihead attention are added together. Z-score standardization is also done across features.

It is then passed through a feedforward network and the encoder output is ready there. There are N number of such blocks in the transformer model.

The output of the encoder is given to the decoder side of the transformer. Output is in the form of Q, and K matrices. The value V matrix is generated by the decoder. There are N number of decoder blocks too in the transformer model. At the output a sequence of words is generated based on the probability as discussed earlier.
Masked multi-head attention is used in the decoder, this means that the model does not have information on the future timestamps from the input (they are masked). Output at each timestamp is given as input in the next timestamp after being converted to embeddings and added into the positional encoding vector.
Impact on NLP
The transformer model was a breakthrough in NLP. Encoders can be used as standalone models as they are very good at learning meaningful representations. As they are capable of understanding the text, they are used for tasks like sentiment analysis, named entity recognition, sentence classification, providing embeddings, etc. Common examples are BERT and its variants like RoBERTa and ALBERT.
Similarly, decoders can also be used as standalone models. They are great at natural language generation tasks. Common examples are GPT, GPT-2, etc. Common encoder-decoder models are T5, BART, M2M100, Pegasus, etc.
Transformers have changed natural language processing by greatly increasing correctness, speed, as well as size. They were introduced in the research paper - Attention Is All You Need (2017). They replaced recurrent models (LSTMs, GRUs) with self-attention mechanisms, resulting in state-of-the-art performance in tasks such as translation, summarization, and question-answering. Unlike standard word vectors, several models like BERT, GPT, and T5 use contextual embeddings, and that enables a subtle grasp of language. A key improvement within them is their capacity to process full sequences in parallel, a capability that can be harnessed when you hire AI developer talent for specialized projects.
The increase of many large language models (GPT-4, Claude, PaLM) has powered multiple AI-driven applications, such as chatbots, code generation, and virtual assistants. Also, transformers have made models such as T5, BART, and Pegasus better at creating abstractive summaries.
Just published



